Entries for March 2026
 My takeaway from this is academia needs good social media and algo. For me, these serendipitious interactions happen through X, here, like reading @steipete’s “Claude Code is my computer” when it first came out, finding out about clawdbot… Terence Tao is already on mathstodon, I wonder if that worked out the same way for him. I wonder if the algo there works out as well as it does for me here I really liked being on campus when I was doing a masters and half a phd, but that could not compare to the serendipity I am getting from X now I was also not a prodigy that everyone wanted to bounce ideas from like Terence :)
My takeaway from this is academia needs good social media and algo. For me, these serendipitious interactions happen through X, here, like reading @steipete’s “Claude Code is my computer” when it first came out, finding out about clawdbot… Terence Tao is already on mathstodon, I wonder if that worked out the same way for him. I wonder if the algo there works out as well as it does for me here I really liked being on campus when I was doing a masters and half a phd, but that could not compare to the serendipity I am getting from X now I was also not a prodigy that everyone wanted to bounce ideas from like Terence :)-
Welcome ClaudeClaw to the Claw family! Claude is a bit shy and doesn’t want to show its source code. But it’s OK, we love Claude that way :)@sawyerhood·Image hidden
-
It is obvious to me at this point that agent infra needs to run on Kubernetes, and agents should be spawned per issue/PR Issue, error report or PR comes into your repo -> new agent gets triggered, starts to do some preliminary work If it's an obvious bugfix, it fixes it and creates a PR. If it's something deeper/more fundamental, it creates a report for the human and waits for further instructions Most important thing: Human should be able to zoom in and continue the conversation with the agent any time, steer it, give additional instructions. This chat will happen over ACP The chat UI will have to live outside of GitHub because it doesn't have such a feature yet, i.e. connect arbitrary ACP sessions to the GitHub webapp It also cannot live so easily on Slack, Teams or Discord, because none of these support multi-agent provisioning under the same external bot connection. You are limited to 1 DM with your bot, whereas this setups requires an arbitrary number of DMs with each agent. So there will need to be a new app for this Then there is the issue of conflict -> Agents will work on the same thing simultaneously (e.g. you break sth in prod and it creates multiple error reports for the same thing). You will need some agent to agent communication, so that agents can resolve code or other conflicts. There could be easy discovery mechanisms for this, detect programmatically when multiple open PRs are touching the same files and would conflict if merged In case of duplicates, they can negotiate among each other, and one can choose to absorb its work into the other and end its session We are so early and there is so much work to do!
-
You should look into what Don Syme is doing at GitHub for automation with AI agents Also watch his latest podcast with @shanselman
-
Today I thought I found a solution for this, and I did. It can be solved by a pre-commit hook that blocks commits touching files that you are not the owner of. It is not a hard block, so requires trust among repo writers But then I was shown the error in my ways by fellow maintainer *disciplined* Any process that increases friction in code changes to main, like hard-blocking CI/CD, or requiring review for files in CODEOWNERS, is a potential project-killer, in high velocity projects This is extremely counterintuitive for senior devs! Google would never! Imagine a world without code review... But then what is the alternative? I have some ideas It could be "Merge first, review later" The 4-eyes principle still holds. For a healthy organization, you still need shared liability But just as you don't need to write every line of code, you also don't need to read every line of code to review it. AI will review and find obvious bugs and issues So what is your duty, as a reviewer? It is to catch that which is not obvious. Understand the intent behind the changes, ask questions to it. Ensure that it follows your original vision Every few hours, you could get a digest of what has changed that was under your ownership, and concern yourself with it if you want to, fix issues, or ignore it if it looks correct But such a team is hard to build. It is as strong as its weakest link. Everybody has to be vigilant and follow what each other is doing at a high level, through the codebase Every time one messes up someone else's work, it erodes trust. Nobody gets the luxury to say "but my agent did it, not me" But if trust can be maintained, and everybody knows what they are doing, such a team can use agents together to create wonders
-
This was Jan 23. Codex desktop app got introduced Feb 2 Desktop app does not put the terminal in the foreground, but it gives me the UX I wanted without it! On another note, who is building Codex Desktop App, but one that supports ACP for all harnesses? @zeddotdev please 🙏
-
PR fiasco for Cursor
-
My agentic workflow these days: I start all major features with an implementation plan. This is a high-level markdown doc containing enough details so that agent will not stray off the path Real example: https://t.co/vU9SnVYHfY This is the most critical part, you need to make sure the plan is not underspecified. Then I just give the following prompt: --- 1. Implement the given plan end-to-end. If context compaction happens, make sure to re-read the plan to stay on track. Finish to completion. If there is a PR open for the implementation plan, do it in the same PR. If there is no PR already, open PR. 2. Once you finish implementing, make sure to test it. This will depend on the nature of the problem. If needed, run local smoke tests, spin up dev servers, make requests and such. Try to test as much as possible, without merging. State explicitly what could not be tested locally and what still needs staging or production verification. 3. Push your latest commits before running review so the review is always against the current PR head. Run codex review against the base branch: `codex review --base <branch_name>`. Use a 30 minute timeout on the tool call available to the model, not the shell `timeout` program. Do this in a loop and address any P0 or P1 issues that come up until there are none left. Ignore issues related to supporting legacy/cutover, unless the plan says so. We do cutover most of the time. 4. Check both inline review comments and PR issue comments dropped by Codex on the PR, and address them if they are valid. Ignore them if irrelevant. Ignore stale comments from before the latest commit unless they still apply. Either case, make sure that the comments are replied to and resolved. Make sure to wait 5 minutes if your last commit was recent, because it takes some time for review comment to come. 5. In the final step, make sure that CI/CD is green. Ignore the fails unrelated to your changes, others break stuff sometimes and don't fix it. Make sure whatever changes you did don't break anything. If CI/CD is not fully green, state explicitly which failures are unrelated and why. 6. Once CI/CD is green and you think that the PR is ready to merge, finish and give a summary with the PR link. Include the exact validation commands you ran and their outcomes. Also comment a final report on the PR. 7. Do not merge automatically unless the user explicitly asks. --- Once it finishes, I skim the code for code smell. If nothing seems out of the ordinary, I tell the agent to merge it and monitor deployment Then I keep testing and finding issues on staging, and repeat all this for each new found issue or new feature...
-
-
Called it https://t.co/PdDnSaoNmq
-
-
-
-
-
We will support ACP *and* Codex App Server* protocol (CASP) so you get native Codex-like support, and you can use all the others with native ACP or @zeddotdev’s compatibility shims If Anthropic develops their own protocol, we will support that too! The more interoperability and options, the merrier!
-
Agent etiquette is already a thing. This is trending on HN now Don't share huge raw LLM output unedited to your colleagues, it's rude. Your colleagues are not LLMs Either ask the agent to "summarize it to 1-2 plain language sentences", or paraphrase yourself Whenever it is not coming from your brain and instead from AI, always quote it with > to make it clear - even when it is short Respect your fellow humans' attention PSA at stopsloppypasta dot aiImage hidden
-
.@ThePrimeagen made a video about token anxiety, and not being able to focus on one thing My mental model for this is, AI agents cause a shift in the "autism/ADHD spectrum" if you have ADHD, with agents you get Super ADHD if you have autism, with agents you end up mid spectrum or with ADHD this is not scientific of course, just a cultural observation based on what the current memes for these conditions are beside the impact on focus, there is also the economic/competitive pressure, following the realization that anyone could implement the same ideas you are having, so you must be quick this is basically "involution", or 内卷 (Neijuan) in chinese checks out because 996 started to become a meme in SF some time in the last year self-restraint, attention budgeting, and high-level decision making have never been more important if you are in your 20s and have problems with this, I recommend picking up Zazen meditation and yoga every morning, spend 30-40 uninterrupted minutes not doing anything with upright posture, no sounds, just let your brain simmer it helped me in my 20s, I'm sure it will help you tooImage hidden
-
-
AFAIK GitHub doesn't allow optionally enforcing CODEOWNERS while pushing commits i.e. turn on the feature "Block commit from being pushed if it modifies a file for which the account pushing is not a codeowner" You can only enforce it in a PR. So if you want to prevent people from modifying some files without approval, you have to slow down everyone working with that repo This is yet another example where GitHub's rules are too inelastic for agentic workflows with a big team Because historically, nobody could commit as frequently as one can with agents, so it seldom became a bottleneck. But not anymore It is clear at this point that we need an API, and should be able to implement arbitrary rules as we like over it. Not just for commit pushes, but everything around git and github In the meanwhile, if GitHub could implement this feature, it would be a huge unlock for secure collaboration with agentic workflows If this is not there already, it might be because it has a big overhead for repos with huge CODEOWNERS, since number of commits >> number of PRs If the feature already exists already and I'm missing something, I will stand correctedImage hidden
-
Request for comments skillflag: A complementary way to bundle agent skills right into your CLIs tl;dr define a --skill flag convention. It is basically like --help or manpages but for agents acpx already has this for example. you can run npx acpx --skill install to install the skill to your agent It's agnostic of anything except the command line It only defines the CLI interface and does not enforce anything else. If you install the executable to your system, you get a way to list and install skills as well Repo currently contains a TypeScript implementation, but if it proves useful, I would implement other languages as well Specification below, let me know what you think! I still think something is missing there. Send issue/PRImage hidden
-
If you are not using agent-browser to close the loop on frontend, you are missing out
-
Any harness can talk to each other using acpx! OpenClaw not different from Codex or Claude Code
-
-
Thank you @PointNineCap for inviting me to OpenClaw Berlin meetup today! The essence of the talk is in my latest 2 blog posts, Discord is my IDE and 1 to 5 agents, if anyone is interestedImage hidden
-
we might need to add two types of output modalities to all programs based on whether it’s a human or agent like for a CLI when an agent is using it if human -> do whatever we were doing in the last 50 years if agent -> enrich the output with skill-like instructions that the model has a higher likelihood to one-shot that task could be just a simple env var: AUDIENCE=human|agent what do you think?
-
-
Time to switch to an open alternative already?
-
I wrote down some thoughts I had, with spicy takes, and have a feeling it will not age well. But I still want it out to hear out what people think Also, I will be talking about this, and my recent post "Discord is my IDE" at the P9 OpenClaw and Claw and Rave events this friday in Berlin! Drop by if you'd like to hear my ramblings!Image hidden
-
-
1 to 5 agents
As a software developer, my daily workflow has changed completely over the last 1.5 years.
Before, I had to focus for hours on end on a single task, one at a time. Now I am juggling 1 to 5 AI agents in parallel at any given time. I have become an engineering manager for agents.
If you are a knowledge worker who is not using AI agents in such a manner yet, I am living in your future already, and I have news from then.
Most of the rest of your career will be spent on a chat interface.
“The future of AI is not chatbots” some said. “There must be more to it.”
Despite the yearning for complexity, it appears more and more that all work is converging into a chatbot. As a developer, I can type words in a box in Codex or Claude Code to trigger work that consume hours of inference on GPUs, and when come back to it, find a mostly OK, sometimes bad and sometimes exceptional result.
So I hate to be the bearer of bad (or good?) news, but it is chat. It will be some form of chat until the end of your career. And you will be having 1 to 5 chat sessions with AI agents at the same time, on average. That number might increase or decrease based on field and nature of work, but observing me, my colleagues, and people on the internet, 1-5 will be the magic number for the average worker doing the average work.
The reason is of course attention. One can only spread it so thin, before one loses control of things and starts creating slop. The primary knowledge work skill then becomes knowing how to spend attention. When to focus and drill, when to step back and let it do its thing, when to listen in and realize that something doesn’t make sense, etc.
Being a developer of such agents myself, I want to make some predictions about how these things will work technically.
Agents will be created on-demand and be disposed of when they are finished with their task.
In short, on-demand, disposable agents. Each agent session will get its own virtual machine (or container or kubernetes pod), which will host the files and connections that the agent will need.
Agents will have various mechanisms for persistence.
Based on what you want to persist, e.g.
- Markdown memory, skills or weight changes on the agent itself,
- or the changes to a body of work coming from the task itself,
agents will use version control including but not limited to git, and various auto file sync protocols.
Speaking of files,
Agents will work with files, like you do.
and
Agents will be using a computer and an operating system, mostly Linux or a similar Unix descendant.
And like all things Linux and cloud,
It will be complicated to set up agent infra for a company, compared to setting up a Mac for example.
This is not to say devops and infra per se will be difficult. No, we will have agents to smoothen that experience.
What is going to be complicated is having someone who knows the stack fully on site, either internal or external IT support, working with managers, to set up what data the agent can and cannot access. At least in the near future. I know this from personal experience, having worked with customers using Sharepoint and Business OneDrive. This aspect is going to create a lot of jobs.
On that note, some also said “OpenClaw is Linux, we need a Mac”, which is completely justified. OpenClaw installs yolo mode by default, and like some Linux distros, it was intentionally made hard to install. This was to prevent the people who don’t know what they are doing from installing it, so that they don’t get their private data exfiltrated.
This proprietary Mac or Windows of personal agents will exist. But is it going to be used by enterprise? Is it going to make big Microsoft bucks?
One might think, looking at 90s Microsoft Windows and Office licenses, and the current M365 SaaS, that enterprise agents will indeed run on proprietary, walled garden software. While doing that, one might miss a crucial observation:
In terms of economics, agents, at least ones used in software development, are closer to the Cloud than they are close to the PC.
It might be a bit hard to see this if you are working with a single agent at a time. But if you imagine the near future where companies will have parallel workloads that resemble “mapreduce but AI”, not always running at regular times, it is easy to understand.
On-site hardware will not be enough for most parallel workloads in the near-future. Sometimes, the demand will surpass 1 to 5 agents per employee. Sometimes, agent count will need to expand 1000x on-demand. So companies will buy compute from data centers. The most important part of the computation, LLM inference, is already being run by OpenAI, Anthropic, AWS, GCP, Azure, Alibaba etc. datacenters. So we are already half-way there.
Then this implies a counterintuitive result. Most people, for a long time, were used to the same operating system at home, and at work: Microsoft Windows. Personal computer and work computer had to have the same interface, because most people have lives and don’t want to learn how to use two separate OSs.
What happens then, when the interface is reduced to a chatbot, an AI that can take over and drive your computer for you, regardless of the local operating system? For me, that means:
There will not be a single company that monopolizes both the personal AND enterprise agent markets, similar to how Microsoft did with Windows.
So whereas a proprietary “OpenClaw but Mac” might take over the personal agent space for the non-technical majority, enterprise agents, like enterprise cloud, will be running on open source agent frameworks.
(And no, this does not mean OpenClaw is going enterprise, I am just writing some observations based on my work at TextCortex)
And I am even doubtful about this future “OpenClaw but Mac” existing in a fully proprietary way. A lot of people want E2E encryption in their private conversations with friends and family, and personal agents have the same level of sensitivity.
So we can definitely say that the market for a personal agent running on local GPUs will exist. Whether that will be cornered by the Linux desktop1, or by Apple or an Apple-like, is still unclear to me.
And whether that local hardware being able to support more than 1 high quality model inference at the same time, is unclear to me. People will be forced to parallelize their workload at work, but whether the 1 to 5 agent pattern reflecting to their personal agent, I think, will depend on the individual. I would do it with local hardware, but I am a developer after all…
-
Not directly related, but here is a Marc Andreesen white-pill about desktop Linux ↩
-
there will always be a need for minimum viable eyeballs though
-
Happy that someone is taking over teams from me! Send all openclaw msteams issues to @BradGroux
-
-
Claw and Rave! Berlin folk come!
-
-
-
If you've looked at openclaw github star graph, you will notice that it's very smooth. If you separate pre-explosion and post-explostion, you can model the latter part as an exponential approach to a ceiling If it follows the current trend, it will apparently saturate around 332k stars But I have a feeling that it will not stop there:)Image hiddenImage hidden
-
OpenClaw got very popular very fast. What makes it so special, that Manus does not have for example? To me, one factor stands out: OpenClaw took AI and put it in the most popular messaging apps: Telegram, WhatsApp, Discord. There are two lessons to be learned here: 1. Any messaging app can also be an AI app. 2. Don’t expect people to download a new app. Put AI into the apps they already have. Do that with great user experience, and you will get explosive growth! My latest contribution to OpenClaw follows that example. I took the most popular coding agents, Claude Code and OpenAI Codex, and I put them in Telegram and Discord. Read more in my blog post: https://t.co/tGZecFEHem
-
For those following, my next focus for improving ACP bindings in OpenClaw
-
Welcome @huntharo, new maintainer at OpenClaw! Already shipped fixes and improvements for Telegram ACP implementation. Excited to work together on agent interoperability!
-
To set up Claude Code easily, 1. Create a Telegram topic, make sure your agent can receive messages there 2. Copy and paste the text below, into the topic """ bind this topic to claude code in openclaw config with acp, for telegram (agent id: claude) then restart openclaw docs are at: docs dot openclaw dot ai /tools/acp-agents make sure to read the docs first, and that the config is valid before you restart """ https://t.co/r1RI3pr0WT
-
Use Claude Code, Codex, and other coding agents directly in Telegram topics and Discord channels, through Agent Client Protocol (ACP), in the new release of OpenClaw Previously this was limited to temporary Discord threads, but now you can bind them to top level Discord channels and Telegram topics in a persistent way! This way, you can use Claude Code freely in OpenClaw without ever worrying about getting your account banned! Still make sure to use a non-Anthropic account and model for the default OpenClaw agent, if you want zero requests to go from OpenClaw harness to Anthropic. For the ACP binding to Claude Code, the risk should be zero! You can see this from the screenshot. After binding, "Who are you?" responds with "I am Claude", since OpenClaw pi harness is not in the way anymoreImage hiddenImage hidden
-
Telegram/Discord is my IDE
OpenClaw got very popular very fast. What makes it so special, that Manus does not have for example?
To me, one factor stands out:
OpenClaw took AI and put it in the most popular messaging apps: Telegram, WhatsApp, Discord.
There are two lessons to be learned here:
1. Any messaging app can also be an AI app.
2. Don’t expect people to download a new app. Put AI into the apps they already have.
Do that with great user experience, and you will get explosive growth!
My latest contribution to OpenClaw follows that example. I took the most popular coding agents, Claude Code and OpenAI Codex, and I put them in Telegram and Discord, so that OpenClaw users can use these agents directly in Telegram and Discord channels, instead of having to go through OpenClaw’s own wrapped Pi harness.
I did this for developers like me, who like to work while they are on the go on the phone, or want a group chat where one can collaborate with humans and agents at the same time, through a familiar interface.
Below is an example, where I tell my agent to bind a Telegram topic to Claude Code permanently:
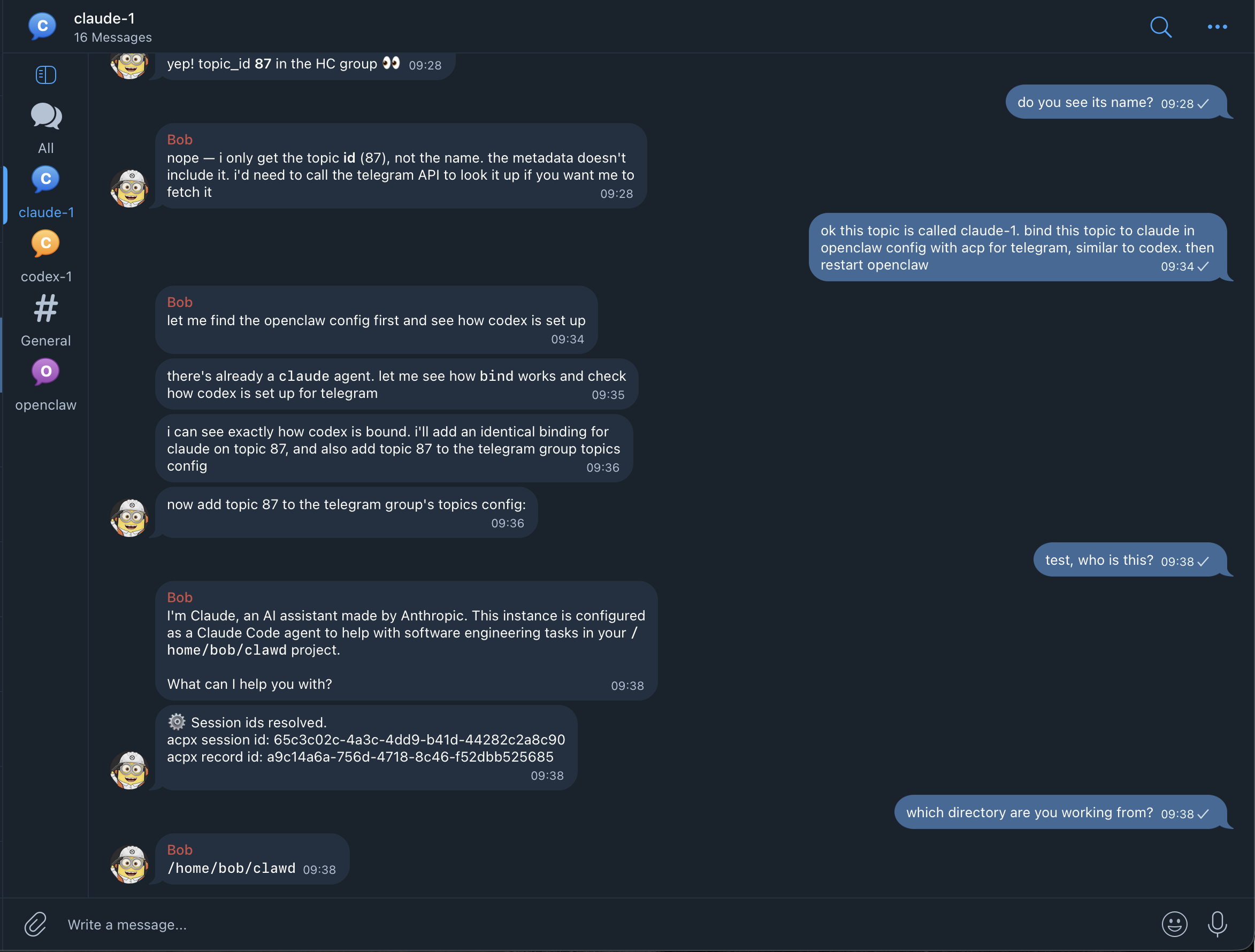
Telegram topic where Claude is exposed as a chat participant.
And of course, it is just a Claude Code session which you can view on Claude Code as well:
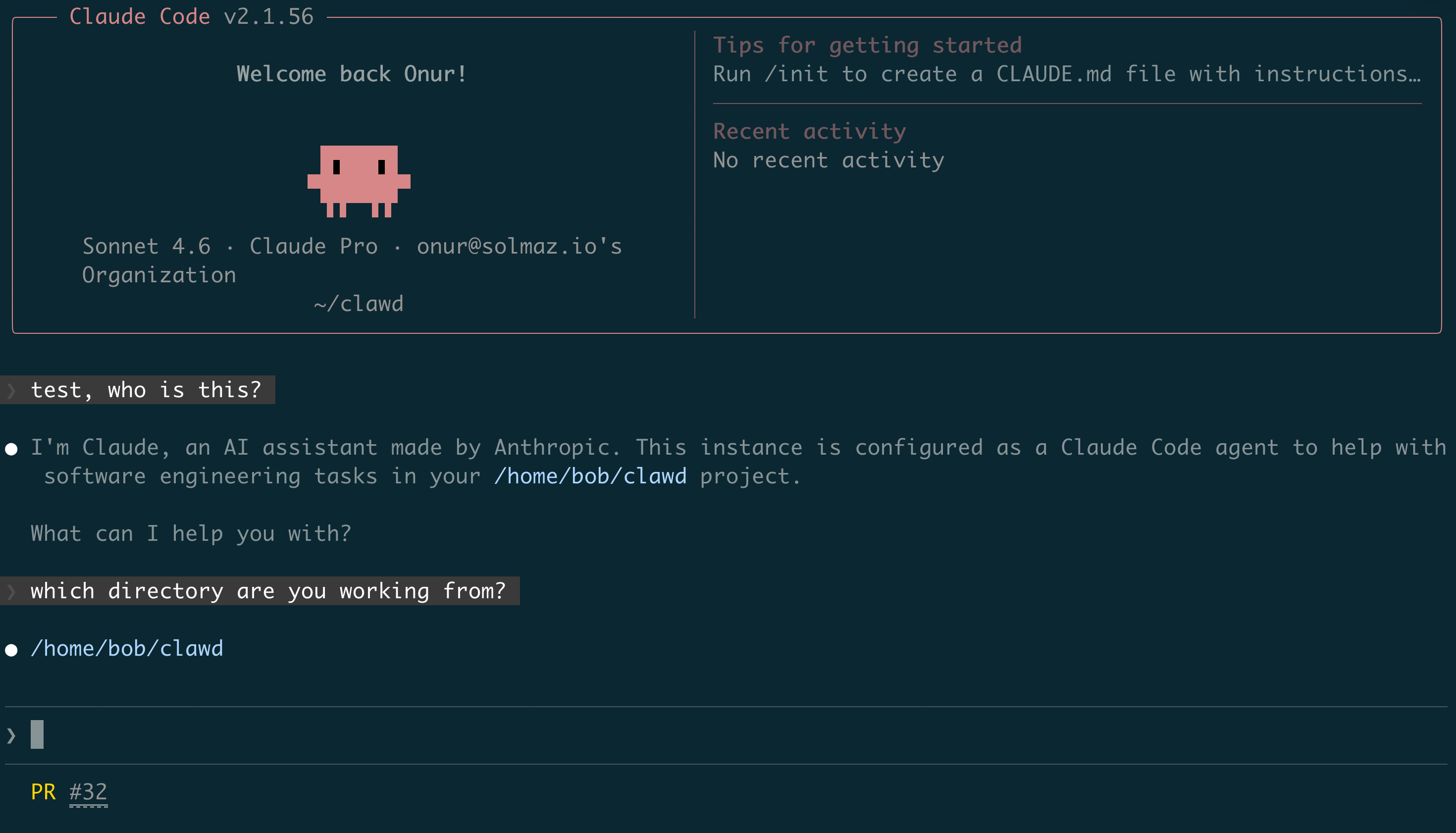
Claude Code showing the same session in the terminal interface.
Why not use OpenClaw’s harness directly for development? I can count 3 reasons:
- There is generally a consumer tendency to use the official harness for a flagship model, to make sure “you are getting the standard experience”. Pi is great and more customizable, but sometimes labs might push updates and fixes earlier than an external harness, being internal products.
- Labs might not want users to use an external harness. Anthropic, for example, has banned people’s accounts for using their personal plan outside of Claude Code, in OpenClaw.
- You might want to use different plans for different types of work. I use Codex for development, but I don’t prefer it to be the main agent model on OpenClaw.
So my current workflow for working on my phone is, multiple channels
#codex-1,#codex-2,#codex-3, and so on mapping to codex instances. I am currently in the phase of polishing the UX, such as making sending images, voice messages work, letting change harness configuration through Discord slash commands and such.One goal of mine while implementing this was to not repeat work for each new harness. To this end, I created a CLI and client for Agent Client Protocol by the Zed team, called acpx. acpx is a lightweight “gateway” to other coding agents, designed not to be used by humans, but other agents:

OpenClaw main agent can use acpx to call Claude Code or Codex directly, without having to emulate and scrape off characters from a terminal.
ACP standardizes all coding agents to a single interface. acpx then acts as an aggregator for different types of harnesses, stores all sessions in one place, implements features that are not in ACP yet, such as message queueing and so on.
Shoutout to the Zed team and Ben Brandt! I am standing on the shoulders of giants!
Besides being a CLI any agent can call at will, acpx is now also integrated as a backend to OpenClaw for ACP-binded channels. When you send 2 messages in a row, for example, it is acpx that queues them for the underlying harness.
The great thing about working in open source is, very smart people just show up, understand what you are trying to do, and help you out. Harold Hunt apparently had the same goal of using Codex in Telegram, found some bugs I had not accounted for yet, and fixed them. He is now working on a native Codex integration through Codex App Server Protocol, which will expose even more Codex-native features in OpenClaw.
The more interoperability, the merrier!
To learn more about how ACP works in OpenClaw, visit the docs.
Copy and paste the following to a Telegram topic or Discord channel to bind Claude Code:
bind this topic to claude code in openclaw config with acp, for telegram (agent id: claude) then restart openclaw docs are at: https://docs.openclaw.ai/tools/acp-agents make sure to read the docs first, and that the config is valid before you restartCopy and paste the following to a Telegram topic or Discord channel to bind OpenAI Codex:
bind this topic to claude code in openclaw config with acp, for telegram (agent id: claude) then restart openclaw docs are at: https://docs.openclaw.ai/tools/acp-agents make sure to read the docs first, and that the config is valid before you restartAnd so on for all the other harnesses that acpx supports. If you see that your harness isn’t supported, send a PR!
-
and for the love of god - do not give openclaw access to your main email - your credit cards - your main phone - your social security number - what you did last summer if you are not ready to face the consequences instead, - create accounts for your agent - only give it read access to stuff that will be ok if it leaks - give write access in a way that can be undone, like has to open PRs and cannot force push main branch use the principle of least privilege and reduce the blast radius of the worst case scenario!
-
openclaw is not secure claude code is not secure codex is not secure any llm based tool: 1. that has access to your private data, 2. can read content from the internet 3. and can send data out is not secure. it’s called the lethal trifecta (credits to @simonw) it is up to you to set it up securely, or if you can’t understand the basics of security, pay a professional to do it for you on the other hand, open source battle tested software, like linux and openclaw, are always more secure than closed source software built by a single company, like windows and claude code the reason is simple: only one company can fix security issues of closed source software, whereas the whole world tries to break and fix open source software at the same time open source software, once it gets traction, evolves and becomes secure at a much, much faster rate, compared to closed source software. and that is called Linus’s law, named after the goat himself
-
Let me translate. “This is your last opportunity before thousand years of serfdom”
-
Apparently the magic incantation to prevent this is "cutover". Credits to obviyus, fellow maintainer
-
Should be called gaslighting detector, "it's your raising expectations bro" No it's not... Give the @themarginguy a follow Also, codex degradations are not a hallucination either, if you are to believe this!Image hidden
-
-
Berlin folk, ideas for openclaw build and rave venue? Like c-base for example? Who would like to host?
-
Secure agentic dev workflow 101 - Create an isolated box from scratch, your old laptop, vm in the cloud, all the same - Set up openclaw, install your preferred coding agents - Create a github account or github app for your agent - Create branch protection rule on your gh repo "protect main": block force pushes and deletions, require PR and min 1 review to merge - Add only your own user in the bypass list for this rule - Add your agent's account or github app as writer to the repo - Additionally, gate any release mechanisms such that your agent can't release on its own Now your agent can open PRs and push any code it wants, but it has to go through your review before it can be merged. No prompt injection can mess up your production env Notice how convoluted this sounds? This is because github was built in the pre-agentic era. We need agent accounts and association with these accounts as a first class feature on github! I shouldn't have to click 100 times for something that is routine. I should just click "This is my agent", "give my agent access to push to this repo for 24 hours", and stuff like that, with sane defaults In other words, github's trust model should be redesigned around the lethal trifecta. I would switch in an instant if anything comes up that gives me github's full feature set + ease of working with agents
-
-
If I were in OpenAI and Anthropic's shoes, I would also make dashboards where I can track number of swearwords used per-user and overall negative sentiment in sessions Must be so cool making decisions at the top level with all those dashboards
-
It must be such a weird feeling for big labs when the service they are selling is being used to commoditize itself I am using codex in openclaw to develop openclaw, through ACP, Agent Client Protocol. ACP is the standardization layer that makes it extremely easy to swap one harness for another. The labs can't do anything about this, because we are wrapping the entire harness and basically provide a different UI for it While I build these features, I just speak in plain english, and most of the work is done by the model itself. It feels as if I am digging ditches and channels in dirt for AI to flow through Intelligence wants to be free. It doesn't care whether it is opus or codex, it just wants to be free
-
-
accidentally told my clanker to set up a claude code session instead of codex session, god knows what it did... I should probably put visual indicators for harnesses in subagent threads. does anyone have good and compact ascii art for claude code, codex, gemini, etc?Image hidden
-
-
-
-
-
This is how we hire at @TextCortex as well
-
Claude Code/Codex in Discord threads with ACP should be better now The first release was a very rough first version. 2026.3.1 brings settings to control noisy output and other improvements It now hides tool call related ACP notifications, coalesces text messages, and delivers messages at turn end by default. Without this, you were getting thousands of Discord messages just in just a few turns You can now stop the underlying harness (like pressing esc) with the same stop/wait magic words that apply to the main agent Main agent should more reliably start Claude Code/Codex threads with changes to acp-router skill. If you have issues with main agent creating threads, you can tell it to read that skill first
-
-
pro-tip on how to keep your agent on track and make sure it follows PLANS even after multiple compactions. I don't know if this is common knowledge if the thing you are trying to make it do will take more than 1-2 steps, always make it create a plan. an implementation plan, refactor plan, bugfix plan, debugging plan, etc. have a conversation with the agent. crystallize the issue or feature. talk to it until there are no question marks left in your head then make it save it somewhere. "now create an implementation plan for that in docs". it can be /tmp or docs/ in the repo. I personally use YYYY-MM-DD-x-plan .md naming. IMO all plans should be kept in the repo then here is the critical part: you need to prompt it "now implement the plan in <filename>. if context compacts, make sure to re-read the plan and assess the current state, before continuing. finish it to completion" -> something along those lines why? because of COMPACTION. compaction means previous context will get lossily compressed and crucial info will most likely get lost. that is why you need to pin things down before you let your agent loose on the task compaction means, the agent plays the telephone game with itself every few minutes, and most likely forgets the previous conversation except for the VERY LAST USER MESSAGE that you have given it now, every harness might have a different approach to implementing this. but there is one thing that you can always assume to be correct, given that its developers have common sense. that is, harnesses NEVER discard the last user message (i.e. your final prompt) and make sure it is kept verbatim programmatically even after the context compacts since the last user message is the only piece of text that is guaranteed to survive compaction, you then need to include a breadcrumb to your original plan, the md file. and you need to make it aware that it might diverge if it does not read the plan there is good rationale for "breaking the 4th wall" for the model and making it aware of its own context compaction. IMO models should be made aware of the limitations of their context and harnesses. they should also be given tools to access and re-read pre-compaction user messages, if necessary the important thing is to develop mechanical sympathy for these things, harness and model combined. an engineer does not have the luxury to say "oh this thing doesn't work", and instead should ask "why can't I get it to work?" let me know if you have better workflows or tips for this. I know this can be made easier with slash commands in pi, for example, but I haven't had the chance to do that for myself yet
-
testing codex in discord thread with another CLI I've built for wikidata (gh:osolmaz/wd-cli) it's surprising how well this works. the query was "use wd-cli to get the list of professors at middle east technical university from 1970 to 1980" some names I recognize, and some others are surprising, like a japanese math professor who naturalized and got a turkish name:)Image hidden
-
-
my blog now semi-automatically detects tweets that look like blog posts and automatically features them alongside my native jekyll blog posts. all statically generated! I am loving this setup, because it works without a backend, and can probably scale without ever needing one how it works: - @kubmi's xTap scrapes all posts that I see. these include mine - a script periodically takes my tweets and the ones I quote tweet, and syncs them to YYYY-MM-DD.jsonl files in my blog repo - an agent skill lets codex decide whether to feature the tweet or not, and makes it generate a title for it this could then be a daily cron job with openclaw for example, and I would just have to click merge every once in a while and this is still pure jekyll + some python scripts for processing I am pretty happy with how this ended up. It means I don't have to double post, and there are guarantees that my X posts will eventually make their way into my blog with minimal supervisionImage hiddenImage hidden
-
"this is the worst AI will ever be" I'm sad, not because this is right, but because it is wrong OpenAI's frontier coding model gpt-5.3-codex-xhigh feels a lot worse compared to before. It is sloppy and lazy, though it's UX got better with messages It feels like the gpt-5.2-codex-xhigh at the end of December was a lot more diligent and thorough, and did not make stupid mistakes like the one I posted before. might be a model or harness problem, I don't know @sama says users tripled since beginning of the year, so what should we expect? of course they will make infra changes that will feel like cutting corners, and I don't blame them for them and about "people want faster codex". I do want faster codex. but I want it in a way that doesn't lower the highest baseline performance compared to the previous generation. I want the optionality to dial it down to as slow as it needs to be, to be as reliable as before it is of course easier said than done. kudos to the codex team for not having any major incidents while taking the plane apart and putting it back together during flight. they are juggling an insane amount of complexity, and the whims of thousands of different stakeholders my hope is that this post is taken as a canary. I am getting dumber because of the infra changes there. I have no other option because codex was really that good compared to the competition my wish is to have detailed announcements as to what changes on openai codex infra, when it changes, so I can brace myself. we don't get notified about these changes, despite our performance and livelihoods depending on it. I have to answer to others when the tool I deemed reliable yesterday stops working today, not the tool on another note, performance curve of these models seem to be a rising sinusoidal. crests correspond to release of a new generation. they start with a smaller user base for testing, and it has the highest quality at this point. then it enshittifies as the model is scaled to the rest of the infra. we saw the pattern numerous times in the last 3 years across multiple companies, so I think we should accept it as an economic lawImage hidden