Entries for 2026
 My takeaway from this is academia needs good social media and algo. For me, these serendipitious interactions happen through X, here, like reading @steipete’s “Claude Code is my computer” when it first came out, finding out about clawdbot… Terence Tao is already on mathstodon, I wonder if that worked out the same way for him. I wonder if the algo there works out as well as it does for me here I really liked being on campus when I was doing a masters and half a phd, but that could not compare to the serendipity I am getting from X now I was also not a prodigy that everyone wanted to bounce ideas from like Terence :)
My takeaway from this is academia needs good social media and algo. For me, these serendipitious interactions happen through X, here, like reading @steipete’s “Claude Code is my computer” when it first came out, finding out about clawdbot… Terence Tao is already on mathstodon, I wonder if that worked out the same way for him. I wonder if the algo there works out as well as it does for me here I really liked being on campus when I was doing a masters and half a phd, but that could not compare to the serendipity I am getting from X now I was also not a prodigy that everyone wanted to bounce ideas from like Terence :)-
Welcome ClaudeClaw to the Claw family! Claude is a bit shy and doesn’t want to show its source code. But it’s OK, we love Claude that way :)@sawyerhood·Image hidden
-
It is obvious to me at this point that agent infra needs to run on Kubernetes, and agents should be spawned per issue/PR Issue, error report or PR comes into your repo -> new agent gets triggered, starts to do some preliminary work If it's an obvious bugfix, it fixes it and creates a PR. If it's something deeper/more fundamental, it creates a report for the human and waits for further instructions Most important thing: Human should be able to zoom in and continue the conversation with the agent any time, steer it, give additional instructions. This chat will happen over ACP The chat UI will have to live outside of GitHub because it doesn't have such a feature yet, i.e. connect arbitrary ACP sessions to the GitHub webapp It also cannot live so easily on Slack, Teams or Discord, because none of these support multi-agent provisioning under the same external bot connection. You are limited to 1 DM with your bot, whereas this setups requires an arbitrary number of DMs with each agent. So there will need to be a new app for this Then there is the issue of conflict -> Agents will work on the same thing simultaneously (e.g. you break sth in prod and it creates multiple error reports for the same thing). You will need some agent to agent communication, so that agents can resolve code or other conflicts. There could be easy discovery mechanisms for this, detect programmatically when multiple open PRs are touching the same files and would conflict if merged In case of duplicates, they can negotiate among each other, and one can choose to absorb its work into the other and end its session We are so early and there is so much work to do!
-
You should look into what Don Syme is doing at GitHub for automation with AI agents Also watch his latest podcast with @shanselman
-
Today I thought I found a solution for this, and I did. It can be solved by a pre-commit hook that blocks commits touching files that you are not the owner of. It is not a hard block, so requires trust among repo writers But then I was shown the error in my ways by fellow maintainer *disciplined* Any process that increases friction in code changes to main, like hard-blocking CI/CD, or requiring review for files in CODEOWNERS, is a potential project-killer, in high velocity projects This is extremely counterintuitive for senior devs! Google would never! Imagine a world without code review... But then what is the alternative? I have some ideas It could be "Merge first, review later" The 4-eyes principle still holds. For a healthy organization, you still need shared liability But just as you don't need to write every line of code, you also don't need to read every line of code to review it. AI will review and find obvious bugs and issues So what is your duty, as a reviewer? It is to catch that which is not obvious. Understand the intent behind the changes, ask questions to it. Ensure that it follows your original vision Every few hours, you could get a digest of what has changed that was under your ownership, and concern yourself with it if you want to, fix issues, or ignore it if it looks correct But such a team is hard to build. It is as strong as its weakest link. Everybody has to be vigilant and follow what each other is doing at a high level, through the codebase Every time one messes up someone else's work, it erodes trust. Nobody gets the luxury to say "but my agent did it, not me" But if trust can be maintained, and everybody knows what they are doing, such a team can use agents together to create wonders
-
This was Jan 23. Codex desktop app got introduced Feb 2 Desktop app does not put the terminal in the foreground, but it gives me the UX I wanted without it! On another note, who is building Codex Desktop App, but one that supports ACP for all harnesses? @zeddotdev please 🙏
-
PR fiasco for Cursor
-
My agentic workflow these days: I start all major features with an implementation plan. This is a high-level markdown doc containing enough details so that agent will not stray off the path Real example: https://t.co/vU9SnVYHfY This is the most critical part, you need to make sure the plan is not underspecified. Then I just give the following prompt: --- 1. Implement the given plan end-to-end. If context compaction happens, make sure to re-read the plan to stay on track. Finish to completion. If there is a PR open for the implementation plan, do it in the same PR. If there is no PR already, open PR. 2. Once you finish implementing, make sure to test it. This will depend on the nature of the problem. If needed, run local smoke tests, spin up dev servers, make requests and such. Try to test as much as possible, without merging. State explicitly what could not be tested locally and what still needs staging or production verification. 3. Push your latest commits before running review so the review is always against the current PR head. Run codex review against the base branch: `codex review --base <branch_name>`. Use a 30 minute timeout on the tool call available to the model, not the shell `timeout` program. Do this in a loop and address any P0 or P1 issues that come up until there are none left. Ignore issues related to supporting legacy/cutover, unless the plan says so. We do cutover most of the time. 4. Check both inline review comments and PR issue comments dropped by Codex on the PR, and address them if they are valid. Ignore them if irrelevant. Ignore stale comments from before the latest commit unless they still apply. Either case, make sure that the comments are replied to and resolved. Make sure to wait 5 minutes if your last commit was recent, because it takes some time for review comment to come. 5. In the final step, make sure that CI/CD is green. Ignore the fails unrelated to your changes, others break stuff sometimes and don't fix it. Make sure whatever changes you did don't break anything. If CI/CD is not fully green, state explicitly which failures are unrelated and why. 6. Once CI/CD is green and you think that the PR is ready to merge, finish and give a summary with the PR link. Include the exact validation commands you ran and their outcomes. Also comment a final report on the PR. 7. Do not merge automatically unless the user explicitly asks. --- Once it finishes, I skim the code for code smell. If nothing seems out of the ordinary, I tell the agent to merge it and monitor deployment Then I keep testing and finding issues on staging, and repeat all this for each new found issue or new feature...
-
-
Called it https://t.co/PdDnSaoNmq
-
-
-
-
-
We will support ACP *and* Codex App Server* protocol (CASP) so you get native Codex-like support, and you can use all the others with native ACP or @zeddotdev’s compatibility shims If Anthropic develops their own protocol, we will support that too! The more interoperability and options, the merrier!
-
Agent etiquette is already a thing. This is trending on HN now Don't share huge raw LLM output unedited to your colleagues, it's rude. Your colleagues are not LLMs Either ask the agent to "summarize it to 1-2 plain language sentences", or paraphrase yourself Whenever it is not coming from your brain and instead from AI, always quote it with > to make it clear - even when it is short Respect your fellow humans' attention PSA at stopsloppypasta dot aiImage hidden
-
.@ThePrimeagen made a video about token anxiety, and not being able to focus on one thing My mental model for this is, AI agents cause a shift in the "autism/ADHD spectrum" if you have ADHD, with agents you get Super ADHD if you have autism, with agents you end up mid spectrum or with ADHD this is not scientific of course, just a cultural observation based on what the current memes for these conditions are beside the impact on focus, there is also the economic/competitive pressure, following the realization that anyone could implement the same ideas you are having, so you must be quick this is basically "involution", or 内卷 (Neijuan) in chinese checks out because 996 started to become a meme in SF some time in the last year self-restraint, attention budgeting, and high-level decision making have never been more important if you are in your 20s and have problems with this, I recommend picking up Zazen meditation and yoga every morning, spend 30-40 uninterrupted minutes not doing anything with upright posture, no sounds, just let your brain simmer it helped me in my 20s, I'm sure it will help you tooImage hidden
-
-
AFAIK GitHub doesn't allow optionally enforcing CODEOWNERS while pushing commits i.e. turn on the feature "Block commit from being pushed if it modifies a file for which the account pushing is not a codeowner" You can only enforce it in a PR. So if you want to prevent people from modifying some files without approval, you have to slow down everyone working with that repo This is yet another example where GitHub's rules are too inelastic for agentic workflows with a big team Because historically, nobody could commit as frequently as one can with agents, so it seldom became a bottleneck. But not anymore It is clear at this point that we need an API, and should be able to implement arbitrary rules as we like over it. Not just for commit pushes, but everything around git and github In the meanwhile, if GitHub could implement this feature, it would be a huge unlock for secure collaboration with agentic workflows If this is not there already, it might be because it has a big overhead for repos with huge CODEOWNERS, since number of commits >> number of PRs If the feature already exists already and I'm missing something, I will stand correctedImage hidden
-
Request for comments skillflag: A complementary way to bundle agent skills right into your CLIs tl;dr define a --skill flag convention. It is basically like --help or manpages but for agents acpx already has this for example. you can run npx acpx --skill install to install the skill to your agent It's agnostic of anything except the command line It only defines the CLI interface and does not enforce anything else. If you install the executable to your system, you get a way to list and install skills as well Repo currently contains a TypeScript implementation, but if it proves useful, I would implement other languages as well Specification below, let me know what you think! I still think something is missing there. Send issue/PRImage hidden
-
If you are not using agent-browser to close the loop on frontend, you are missing out
-
Any harness can talk to each other using acpx! OpenClaw not different from Codex or Claude Code
-
-
Thank you @PointNineCap for inviting me to OpenClaw Berlin meetup today! The essence of the talk is in my latest 2 blog posts, Discord is my IDE and 1 to 5 agents, if anyone is interestedImage hidden
-
we might need to add two types of output modalities to all programs based on whether it’s a human or agent like for a CLI when an agent is using it if human -> do whatever we were doing in the last 50 years if agent -> enrich the output with skill-like instructions that the model has a higher likelihood to one-shot that task could be just a simple env var: AUDIENCE=human|agent what do you think?
-
-
Time to switch to an open alternative already?
-
I wrote down some thoughts I had, with spicy takes, and have a feeling it will not age well. But I still want it out to hear out what people think Also, I will be talking about this, and my recent post "Discord is my IDE" at the P9 OpenClaw and Claw and Rave events this friday in Berlin! Drop by if you'd like to hear my ramblings!Image hidden
-
-
1 to 5 agents
As a software developer, my daily workflow has changed completely over the last 1.5 years.
Before, I had to focus for hours on end on a single task, one at a time. Now I am juggling 1 to 5 AI agents in parallel at any given time. I have become an engineering manager for agents.
If you are a knowledge worker who is not using AI agents in such a manner yet, I am living in your future already, and I have news from then.
Most of the rest of your career will be spent on a chat interface.
“The future of AI is not chatbots” some said. “There must be more to it.”
Despite the yearning for complexity, it appears more and more that all work is converging into a chatbot. As a developer, I can type words in a box in Codex or Claude Code to trigger work that consume hours of inference on GPUs, and when come back to it, find a mostly OK, sometimes bad and sometimes exceptional result.
So I hate to be the bearer of bad (or good?) news, but it is chat. It will be some form of chat until the end of your career. And you will be having 1 to 5 chat sessions with AI agents at the same time, on average. That number might increase or decrease based on field and nature of work, but observing me, my colleagues, and people on the internet, 1-5 will be the magic number for the average worker doing the average work.
The reason is of course attention. One can only spread it so thin, before one loses control of things and starts creating slop. The primary knowledge work skill then becomes knowing how to spend attention. When to focus and drill, when to step back and let it do its thing, when to listen in and realize that something doesn’t make sense, etc.
Being a developer of such agents myself, I want to make some predictions about how these things will work technically.
Agents will be created on-demand and be disposed of when they are finished with their task.
In short, on-demand, disposable agents. Each agent session will get its own virtual machine (or container or kubernetes pod), which will host the files and connections that the agent will need.
Agents will have various mechanisms for persistence.
Based on what you want to persist, e.g.
- Markdown memory, skills or weight changes on the agent itself,
- or the changes to a body of work coming from the task itself,
agents will use version control including but not limited to git, and various auto file sync protocols.
Speaking of files,
Agents will work with files, like you do.
and
Agents will be using a computer and an operating system, mostly Linux or a similar Unix descendant.
And like all things Linux and cloud,
It will be complicated to set up agent infra for a company, compared to setting up a Mac for example.
This is not to say devops and infra per se will be difficult. No, we will have agents to smoothen that experience.
What is going to be complicated is having someone who knows the stack fully on site, either internal or external IT support, working with managers, to set up what data the agent can and cannot access. At least in the near future. I know this from personal experience, having worked with customers using Sharepoint and Business OneDrive. This aspect is going to create a lot of jobs.
On that note, some also said “OpenClaw is Linux, we need a Mac”, which is completely justified. OpenClaw installs yolo mode by default, and like some Linux distros, it was intentionally made hard to install. This was to prevent the people who don’t know what they are doing from installing it, so that they don’t get their private data exfiltrated.
This proprietary Mac or Windows of personal agents will exist. But is it going to be used by enterprise? Is it going to make big Microsoft bucks?
One might think, looking at 90s Microsoft Windows and Office licenses, and the current M365 SaaS, that enterprise agents will indeed run on proprietary, walled garden software. While doing that, one might miss a crucial observation:
In terms of economics, agents, at least ones used in software development, are closer to the Cloud than they are close to the PC.
It might be a bit hard to see this if you are working with a single agent at a time. But if you imagine the near future where companies will have parallel workloads that resemble “mapreduce but AI”, not always running at regular times, it is easy to understand.
On-site hardware will not be enough for most parallel workloads in the near-future. Sometimes, the demand will surpass 1 to 5 agents per employee. Sometimes, agent count will need to expand 1000x on-demand. So companies will buy compute from data centers. The most important part of the computation, LLM inference, is already being run by OpenAI, Anthropic, AWS, GCP, Azure, Alibaba etc. datacenters. So we are already half-way there.
Then this implies a counterintuitive result. Most people, for a long time, were used to the same operating system at home, and at work: Microsoft Windows. Personal computer and work computer had to have the same interface, because most people have lives and don’t want to learn how to use two separate OSs.
What happens then, when the interface is reduced to a chatbot, an AI that can take over and drive your computer for you, regardless of the local operating system? For me, that means:
There will not be a single company that monopolizes both the personal AND enterprise agent markets, similar to how Microsoft did with Windows.
So whereas a proprietary “OpenClaw but Mac” might take over the personal agent space for the non-technical majority, enterprise agents, like enterprise cloud, will be running on open source agent frameworks.
(And no, this does not mean OpenClaw is going enterprise, I am just writing some observations based on my work at TextCortex)
And I am even doubtful about this future “OpenClaw but Mac” existing in a fully proprietary way. A lot of people want E2E encryption in their private conversations with friends and family, and personal agents have the same level of sensitivity.
So we can definitely say that the market for a personal agent running on local GPUs will exist. Whether that will be cornered by the Linux desktop1, or by Apple or an Apple-like, is still unclear to me.
And whether that local hardware being able to support more than 1 high quality model inference at the same time, is unclear to me. People will be forced to parallelize their workload at work, but whether the 1 to 5 agent pattern reflecting to their personal agent, I think, will depend on the individual. I would do it with local hardware, but I am a developer after all…
-
Not directly related, but here is a Marc Andreesen white-pill about desktop Linux ↩
-
there will always be a need for minimum viable eyeballs though
-
Happy that someone is taking over teams from me! Send all openclaw msteams issues to @BradGroux
-
-
Claw and Rave! Berlin folk come!
-
-
-
If you've looked at openclaw github star graph, you will notice that it's very smooth. If you separate pre-explosion and post-explostion, you can model the latter part as an exponential approach to a ceiling If it follows the current trend, it will apparently saturate around 332k stars But I have a feeling that it will not stop there:)Image hiddenImage hidden
-
OpenClaw got very popular very fast. What makes it so special, that Manus does not have for example? To me, one factor stands out: OpenClaw took AI and put it in the most popular messaging apps: Telegram, WhatsApp, Discord. There are two lessons to be learned here: 1. Any messaging app can also be an AI app. 2. Don’t expect people to download a new app. Put AI into the apps they already have. Do that with great user experience, and you will get explosive growth! My latest contribution to OpenClaw follows that example. I took the most popular coding agents, Claude Code and OpenAI Codex, and I put them in Telegram and Discord. Read more in my blog post: https://t.co/tGZecFEHem
-
For those following, my next focus for improving ACP bindings in OpenClaw
-
Welcome @huntharo, new maintainer at OpenClaw! Already shipped fixes and improvements for Telegram ACP implementation. Excited to work together on agent interoperability!
-
To set up Claude Code easily, 1. Create a Telegram topic, make sure your agent can receive messages there 2. Copy and paste the text below, into the topic """ bind this topic to claude code in openclaw config with acp, for telegram (agent id: claude) then restart openclaw docs are at: docs dot openclaw dot ai /tools/acp-agents make sure to read the docs first, and that the config is valid before you restart """ https://t.co/r1RI3pr0WT
-
Use Claude Code, Codex, and other coding agents directly in Telegram topics and Discord channels, through Agent Client Protocol (ACP), in the new release of OpenClaw Previously this was limited to temporary Discord threads, but now you can bind them to top level Discord channels and Telegram topics in a persistent way! This way, you can use Claude Code freely in OpenClaw without ever worrying about getting your account banned! Still make sure to use a non-Anthropic account and model for the default OpenClaw agent, if you want zero requests to go from OpenClaw harness to Anthropic. For the ACP binding to Claude Code, the risk should be zero! You can see this from the screenshot. After binding, "Who are you?" responds with "I am Claude", since OpenClaw pi harness is not in the way anymoreImage hiddenImage hidden
-
Telegram/Discord is my IDE
OpenClaw got very popular very fast. What makes it so special, that Manus does not have for example?
To me, one factor stands out:
OpenClaw took AI and put it in the most popular messaging apps: Telegram, WhatsApp, Discord.
There are two lessons to be learned here:
1. Any messaging app can also be an AI app.
2. Don’t expect people to download a new app. Put AI into the apps they already have.
Do that with great user experience, and you will get explosive growth!
My latest contribution to OpenClaw follows that example. I took the most popular coding agents, Claude Code and OpenAI Codex, and I put them in Telegram and Discord, so that OpenClaw users can use these agents directly in Telegram and Discord channels, instead of having to go through OpenClaw’s own wrapped Pi harness.
I did this for developers like me, who like to work while they are on the go on the phone, or want a group chat where one can collaborate with humans and agents at the same time, through a familiar interface.
Below is an example, where I tell my agent to bind a Telegram topic to Claude Code permanently:
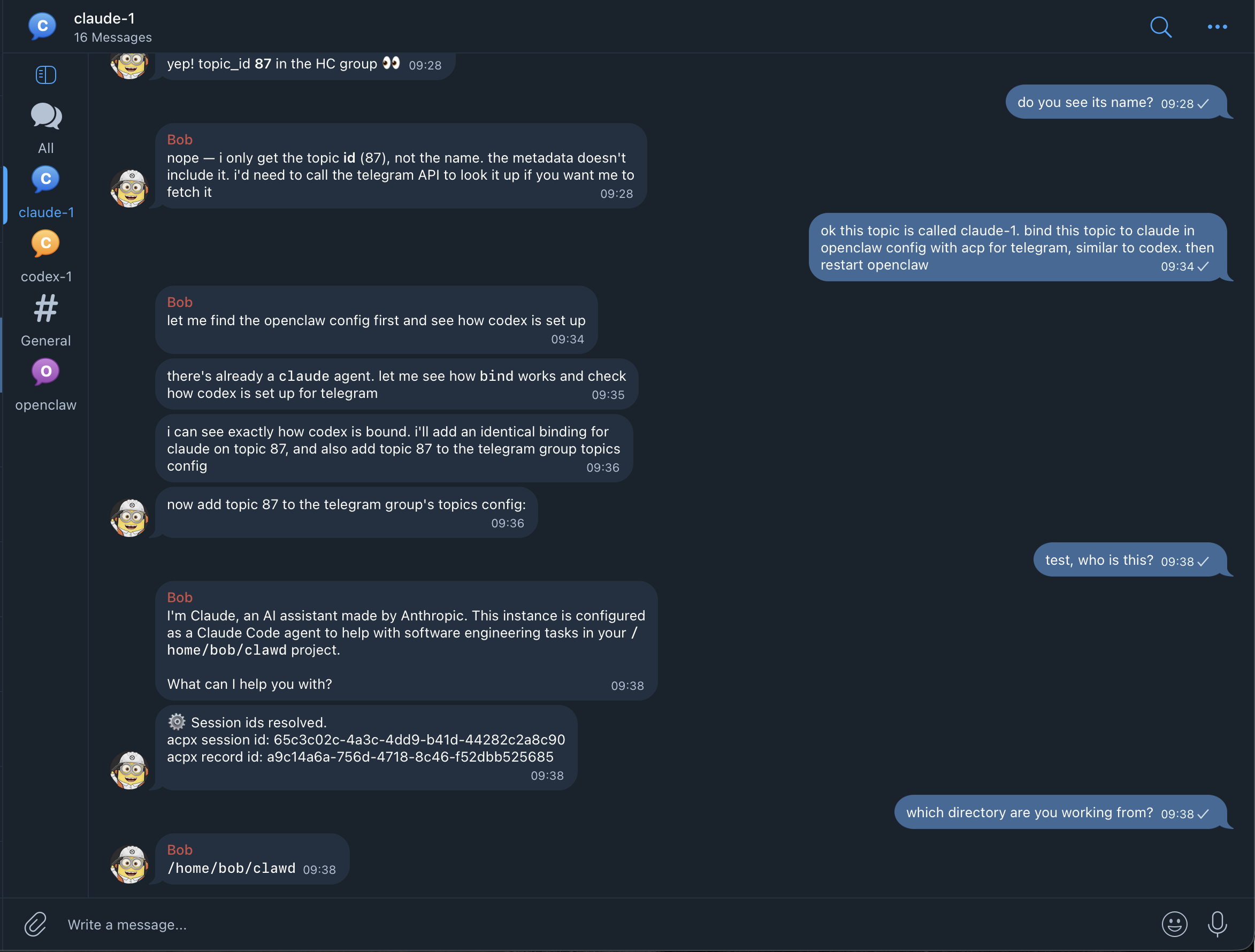
Telegram topic where Claude is exposed as a chat participant.
And of course, it is just a Claude Code session which you can view on Claude Code as well:
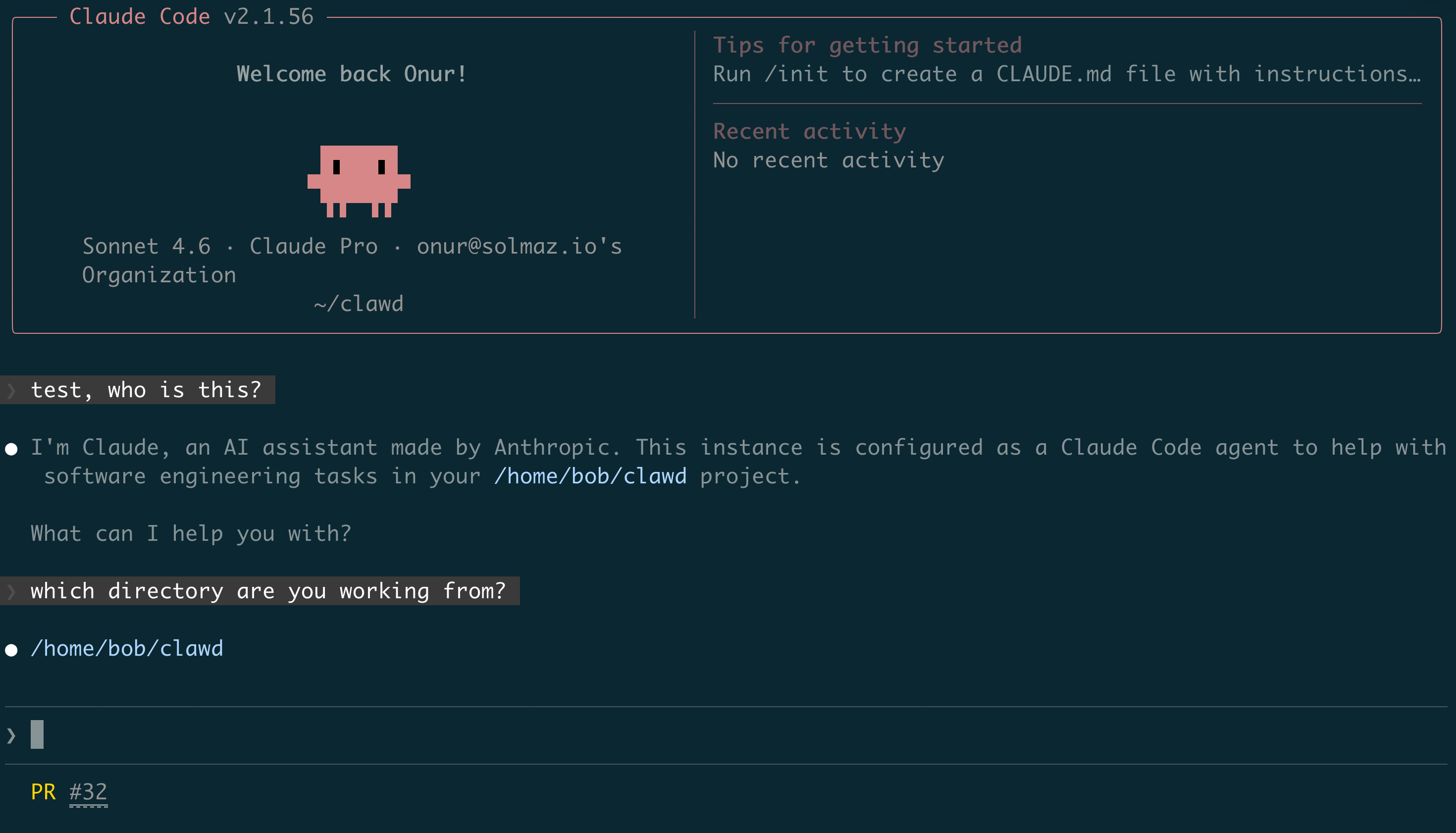
Claude Code showing the same session in the terminal interface.
Why not use OpenClaw’s harness directly for development? I can count 3 reasons:
- There is generally a consumer tendency to use the official harness for a flagship model, to make sure “you are getting the standard experience”. Pi is great and more customizable, but sometimes labs might push updates and fixes earlier than an external harness, being internal products.
- Labs might not want users to use an external harness. Anthropic, for example, has banned people’s accounts for using their personal plan outside of Claude Code, in OpenClaw.
- You might want to use different plans for different types of work. I use Codex for development, but I don’t prefer it to be the main agent model on OpenClaw.
So my current workflow for working on my phone is, multiple channels
#codex-1,#codex-2,#codex-3, and so on mapping to codex instances. I am currently in the phase of polishing the UX, such as making sending images, voice messages work, letting change harness configuration through Discord slash commands and such.One goal of mine while implementing this was to not repeat work for each new harness. To this end, I created a CLI and client for Agent Client Protocol by the Zed team, called acpx. acpx is a lightweight “gateway” to other coding agents, designed not to be used by humans, but other agents:

OpenClaw main agent can use acpx to call Claude Code or Codex directly, without having to emulate and scrape off characters from a terminal.
ACP standardizes all coding agents to a single interface. acpx then acts as an aggregator for different types of harnesses, stores all sessions in one place, implements features that are not in ACP yet, such as message queueing and so on.
Shoutout to the Zed team and Ben Brandt! I am standing on the shoulders of giants!
Besides being a CLI any agent can call at will, acpx is now also integrated as a backend to OpenClaw for ACP-binded channels. When you send 2 messages in a row, for example, it is acpx that queues them for the underlying harness.
The great thing about working in open source is, very smart people just show up, understand what you are trying to do, and help you out. Harold Hunt apparently had the same goal of using Codex in Telegram, found some bugs I had not accounted for yet, and fixed them. He is now working on a native Codex integration through Codex App Server Protocol, which will expose even more Codex-native features in OpenClaw.
The more interoperability, the merrier!
To learn more about how ACP works in OpenClaw, visit the docs.
Copy and paste the following to a Telegram topic or Discord channel to bind Claude Code:
bind this topic to claude code in openclaw config with acp, for telegram (agent id: claude) then restart openclaw docs are at: https://docs.openclaw.ai/tools/acp-agents make sure to read the docs first, and that the config is valid before you restartCopy and paste the following to a Telegram topic or Discord channel to bind OpenAI Codex:
bind this topic to claude code in openclaw config with acp, for telegram (agent id: claude) then restart openclaw docs are at: https://docs.openclaw.ai/tools/acp-agents make sure to read the docs first, and that the config is valid before you restartAnd so on for all the other harnesses that acpx supports. If you see that your harness isn’t supported, send a PR!
-
and for the love of god - do not give openclaw access to your main email - your credit cards - your main phone - your social security number - what you did last summer if you are not ready to face the consequences instead, - create accounts for your agent - only give it read access to stuff that will be ok if it leaks - give write access in a way that can be undone, like has to open PRs and cannot force push main branch use the principle of least privilege and reduce the blast radius of the worst case scenario!
-
openclaw is not secure claude code is not secure codex is not secure any llm based tool: 1. that has access to your private data, 2. can read content from the internet 3. and can send data out is not secure. it’s called the lethal trifecta (credits to @simonw) it is up to you to set it up securely, or if you can’t understand the basics of security, pay a professional to do it for you on the other hand, open source battle tested software, like linux and openclaw, are always more secure than closed source software built by a single company, like windows and claude code the reason is simple: only one company can fix security issues of closed source software, whereas the whole world tries to break and fix open source software at the same time open source software, once it gets traction, evolves and becomes secure at a much, much faster rate, compared to closed source software. and that is called Linus’s law, named after the goat himself
-
Let me translate. “This is your last opportunity before thousand years of serfdom”
-
Apparently the magic incantation to prevent this is "cutover". Credits to obviyus, fellow maintainer
-
Should be called gaslighting detector, "it's your raising expectations bro" No it's not... Give the @themarginguy a follow Also, codex degradations are not a hallucination either, if you are to believe this!Image hidden
-
-
Berlin folk, ideas for openclaw build and rave venue? Like c-base for example? Who would like to host?
-
Secure agentic dev workflow 101 - Create an isolated box from scratch, your old laptop, vm in the cloud, all the same - Set up openclaw, install your preferred coding agents - Create a github account or github app for your agent - Create branch protection rule on your gh repo "protect main": block force pushes and deletions, require PR and min 1 review to merge - Add only your own user in the bypass list for this rule - Add your agent's account or github app as writer to the repo - Additionally, gate any release mechanisms such that your agent can't release on its own Now your agent can open PRs and push any code it wants, but it has to go through your review before it can be merged. No prompt injection can mess up your production env Notice how convoluted this sounds? This is because github was built in the pre-agentic era. We need agent accounts and association with these accounts as a first class feature on github! I shouldn't have to click 100 times for something that is routine. I should just click "This is my agent", "give my agent access to push to this repo for 24 hours", and stuff like that, with sane defaults In other words, github's trust model should be redesigned around the lethal trifecta. I would switch in an instant if anything comes up that gives me github's full feature set + ease of working with agents
-
-
If I were in OpenAI and Anthropic's shoes, I would also make dashboards where I can track number of swearwords used per-user and overall negative sentiment in sessions Must be so cool making decisions at the top level with all those dashboards
-
It must be such a weird feeling for big labs when the service they are selling is being used to commoditize itself I am using codex in openclaw to develop openclaw, through ACP, Agent Client Protocol. ACP is the standardization layer that makes it extremely easy to swap one harness for another. The labs can't do anything about this, because we are wrapping the entire harness and basically provide a different UI for it While I build these features, I just speak in plain english, and most of the work is done by the model itself. It feels as if I am digging ditches and channels in dirt for AI to flow through Intelligence wants to be free. It doesn't care whether it is opus or codex, it just wants to be free
-
-
accidentally told my clanker to set up a claude code session instead of codex session, god knows what it did... I should probably put visual indicators for harnesses in subagent threads. does anyone have good and compact ascii art for claude code, codex, gemini, etc?Image hidden
-
-
-
-
-
This is how we hire at @TextCortex as well
-
Claude Code/Codex in Discord threads with ACP should be better now The first release was a very rough first version. 2026.3.1 brings settings to control noisy output and other improvements It now hides tool call related ACP notifications, coalesces text messages, and delivers messages at turn end by default. Without this, you were getting thousands of Discord messages just in just a few turns You can now stop the underlying harness (like pressing esc) with the same stop/wait magic words that apply to the main agent Main agent should more reliably start Claude Code/Codex threads with changes to acp-router skill. If you have issues with main agent creating threads, you can tell it to read that skill first
-
-
pro-tip on how to keep your agent on track and make sure it follows PLANS even after multiple compactions. I don't know if this is common knowledge if the thing you are trying to make it do will take more than 1-2 steps, always make it create a plan. an implementation plan, refactor plan, bugfix plan, debugging plan, etc. have a conversation with the agent. crystallize the issue or feature. talk to it until there are no question marks left in your head then make it save it somewhere. "now create an implementation plan for that in docs". it can be /tmp or docs/ in the repo. I personally use YYYY-MM-DD-x-plan .md naming. IMO all plans should be kept in the repo then here is the critical part: you need to prompt it "now implement the plan in <filename>. if context compacts, make sure to re-read the plan and assess the current state, before continuing. finish it to completion" -> something along those lines why? because of COMPACTION. compaction means previous context will get lossily compressed and crucial info will most likely get lost. that is why you need to pin things down before you let your agent loose on the task compaction means, the agent plays the telephone game with itself every few minutes, and most likely forgets the previous conversation except for the VERY LAST USER MESSAGE that you have given it now, every harness might have a different approach to implementing this. but there is one thing that you can always assume to be correct, given that its developers have common sense. that is, harnesses NEVER discard the last user message (i.e. your final prompt) and make sure it is kept verbatim programmatically even after the context compacts since the last user message is the only piece of text that is guaranteed to survive compaction, you then need to include a breadcrumb to your original plan, the md file. and you need to make it aware that it might diverge if it does not read the plan there is good rationale for "breaking the 4th wall" for the model and making it aware of its own context compaction. IMO models should be made aware of the limitations of their context and harnesses. they should also be given tools to access and re-read pre-compaction user messages, if necessary the important thing is to develop mechanical sympathy for these things, harness and model combined. an engineer does not have the luxury to say "oh this thing doesn't work", and instead should ask "why can't I get it to work?" let me know if you have better workflows or tips for this. I know this can be made easier with slash commands in pi, for example, but I haven't had the chance to do that for myself yet
-
testing codex in discord thread with another CLI I've built for wikidata (gh:osolmaz/wd-cli) it's surprising how well this works. the query was "use wd-cli to get the list of professors at middle east technical university from 1970 to 1980" some names I recognize, and some others are surprising, like a japanese math professor who naturalized and got a turkish name:)Image hidden
-
-
my blog now semi-automatically detects tweets that look like blog posts and automatically features them alongside my native jekyll blog posts. all statically generated! I am loving this setup, because it works without a backend, and can probably scale without ever needing one how it works: - @kubmi's xTap scrapes all posts that I see. these include mine - a script periodically takes my tweets and the ones I quote tweet, and syncs them to YYYY-MM-DD.jsonl files in my blog repo - an agent skill lets codex decide whether to feature the tweet or not, and makes it generate a title for it this could then be a daily cron job with openclaw for example, and I would just have to click merge every once in a while and this is still pure jekyll + some python scripts for processing I am pretty happy with how this ended up. It means I don't have to double post, and there are guarantees that my X posts will eventually make their way into my blog with minimal supervisionImage hiddenImage hidden
-
"this is the worst AI will ever be" I'm sad, not because this is right, but because it is wrong OpenAI's frontier coding model gpt-5.3-codex-xhigh feels a lot worse compared to before. It is sloppy and lazy, though it's UX got better with messages It feels like the gpt-5.2-codex-xhigh at the end of December was a lot more diligent and thorough, and did not make stupid mistakes like the one I posted before. might be a model or harness problem, I don't know @sama says users tripled since beginning of the year, so what should we expect? of course they will make infra changes that will feel like cutting corners, and I don't blame them for them and about "people want faster codex". I do want faster codex. but I want it in a way that doesn't lower the highest baseline performance compared to the previous generation. I want the optionality to dial it down to as slow as it needs to be, to be as reliable as before it is of course easier said than done. kudos to the codex team for not having any major incidents while taking the plane apart and putting it back together during flight. they are juggling an insane amount of complexity, and the whims of thousands of different stakeholders my hope is that this post is taken as a canary. I am getting dumber because of the infra changes there. I have no other option because codex was really that good compared to the competition my wish is to have detailed announcements as to what changes on openai codex infra, when it changes, so I can brace myself. we don't get notified about these changes, despite our performance and livelihoods depending on it. I have to answer to others when the tool I deemed reliable yesterday stops working today, not the tool on another note, performance curve of these models seem to be a rising sinusoidal. crests correspond to release of a new generation. they start with a smaller user base for testing, and it has the highest quality at this point. then it enshittifies as the model is scaled to the rest of the infra. we saw the pattern numerous times in the last 3 years across multiple companies, so I think we should accept it as an economic lawImage hidden
-
I created a semi-automated setup for ingesting X posts into my blog, and it works pretty well! I own my posts on X now Posts are scraped while I browse X using @kubmi's xTap and get automatically synced to my blog repo. Posts saved as jsonl are then converted to jekyll post pages according to my liking I reproduced the full X UI/UX, minus stuff like like count. Now all my posts are backed up in my blog, and they are safe even if something happens to my account here! The posts are even served over RSS! So you can subscribe to it without going through X! Reply if you want to set this up for yourself, then I will put some effort into standardizing itImage hidden
-
Agentic Engineering is a newly emerging field, and we are the first practitioners of it. Currently there is a lot of experimentation going on, and there is a large aspect to it that is more ART then engineering For example, @steipete says "you need to talk to the model" to get a feel. a lot of work around refining how an agent feels like, sounds like psychology. this part is crucial and should not be ignored, looking at openclaw's success but then there is the hardcore engineering part of it, e.g. Cursor creating a browser or anthropic a C compiler from scratch fully autonomously and there is a whole other dimension of how to teach all software developers this new discipline, lest they be jobless what is obvious is that everybody is trying to grasp for things in the dark and that we need more RIGOR. the art/psychology aspect of it aside, we need solid engineering fundamentals the "thermodynamics" of this new discipline will most likely be formal verification and program synthesis. we might have some breakthroughs that will make certain things clear. the products of it will most likely include a new programming language optimized for agents and the speed of inference moreover, it would be foolish to thing agentic engineering is limited to software. it will penetrate every aspect of the economy, bits AND atoms. it will over time evolve into the engineering of managing robots @simonw is now leading in collecting very useful info from the practitioner's point of view, I highly recommend you to follow this thread let's formalize our new field together!Image hidden
-
-
who remembers ultrathink https://t.co/ftCauqiKx6@onusoz·When you tell Claude Code to ultrathinkImage hidden
-
-
-
-
Claude Code / Codex in Discord threads is shipped now! To enable, copy and paste this to your agent: ``` Enable feature flags: acp.enabled=true acp.dispatch.enabled=true channels.discord.threadBindings.spawnAcpSessions=true Then restart. After restarting: Start a codex (or claude code) discord thread using ACP, persistent session, just tell it to write a haiku on lobsters to initialize acpx for the first time ``` You may need to nudge your agent to “continue” after restarting The first implementation is very barebones, I have made it work in a clean way and merged. In a codebase like openclaw’s, it’s better to develop incrementally Please send any issues my way. I am already aware of some and working on to fix them
-
-
-
-
MIT License on everything from now on. It doesn't make sense to use anything else, except for a few large projects that hyperscalers exploit and not give back If you were making money from a niche app, open source it under MIT License If you had an open source project with GPT, convert it into MIT Extreme involution is about to hit open source. Code is virtually free now. If you want your projects and their brand to survive, the only rational strategy is to remove all barriers in front of their adoption, and look for other ways to survive
-
-
This. Agent Experience first. Agent Ergonomics. we need to get used to these terms
-
OpenAI nerfed GPT 5.3 Codex xhigh. We independently reported the same thing at @TextCortex today I'm looking forward to deploying open models and putting an end to this paranoia
-
"academics"
-
-
-
-
imagine if tarantino were 16 years old now and saw seedance 2.0 95% of videos i saw since the launch for absolute tasteless slop. they are going viral because of ragebait but soon, serious imagineers will start entering the game, and they will learn to shape generation output exactly how they want it's the best time to be young and full of imagination
-
The future is so bright @ladybirdbrowserImage hidden
-
your margin is my opportunity
-
-
-
-
-
another thought i'm having these days is that we need a new philosophy of free software (as in freedom), or an update to it the most psychologically imprinting philosophy is stallmanism, and the philosophy of FSF. it is righteous and strict, and i believed it growing up but GPL and money don't go well together. that's why most of the lasting open source projects today use MIT, Apache and the like. it turns out you can still make a good living with open source. i want to make money, so i never use GPL in my projects and to add another deadly blow to stallmanism, code is cheap now, virtually free does this mean stallmanism is dead? if there is an open source project using GPL that i want to use commercially, i can now recreate it from the original idea and intent completely independent of it (ignoring training data), just like how i can recreate a proprietary service stallmanism was already long-irrelevant. but does this mean we must finally declare it dead? code is free now. what does it mean for open source? what replaces stallmanism?
-
-
one effect openclaw had on me is that I've bought a gpu home server, set it up with tailscale and now doing a lot of work through ssh and tmux like i did 10-15 years ago im back on linux, considering buying an android phone again it's time to dream big again and unshackle ourselves from proprietary software. it's time to build
-
I am asking once again Who is building a self hostable discord clone that supports token streaming? PLEASE I beg you I don’t want another side project 💀
-
In the new release OpenClaw, you can talk to subagents in Discord threads Currently a beta feature so ask your agent to set session.threadBindings.enabled=true Next up: - Telegram, slack, imsg threads - Use ACP to talk to Codex, Claude Code and other harnesses on your machineImage hidden
-
-
openclaw might be the highest velocity codebase in the world, and soon, others will follow as well conflict anxiety is real, it's like trying to shoot a moving target every time. I wonder if our existing tooling will ever solve this problem feel like faster models might. but then the rate of conflict creation is also tied to that. might be unsolvable
-
Getting there https://t.co/jqSNcH2PSyImage hidden
-
-
I am about kick Discord Driven Development up a notch today, stay tuned
-
Imagine not having to upload skills to 3-4 competing skill registries for each of your projects Turns out we already have a skill registry: npm skillflag lets you bundle skills right into your CLI's npm package, so that you can run --skill install github -> osolmaz/skillflagImage hidden
-
-
-
Farmable land if it were as cheap to manufacture as software
-
@kepano I would grow my own vegetables if I had equally cheap access to and ownership of land, alas I am disenfranchised Prompting an agent is much easier compared to plowing a fields Farming analogies break when it comes to software https://t.co/CkldO8eWKc
-
-
If anyone is curious how to build this with open tooling, stay tuned What I'm building at @TextCortex will give you a fully customizable hackable Kubernetes control plane to launch agents on your codebase
-
on another note, I do believe AI will play a huge part in families growing up in late 90s, my dad taught me the importance of reading newspapers and being informed of the world. my nickname in middle school was "newspaper boy" for a long time because I read the newspaper in class on September 12, 2001. i was 10 years old then I witnessed the enshittification of media and journalism in the following decades. today, serious journalists are setting up their own boutique agencies and bypassing mainstream media. important news land on individual accounts before mainstream agencies but there is simply too much to consume. something must filter out the noise and digest the info according to the family's preferences i think AI will play a big role in family intelligence. proprietary family heirloom AI, weights fully owned by the family it will be the parents' job to filter out the signal from the noise, and train the AI on what is right and what is wrong for the family. family and friend circles will let their AIs talk to each other and share important information consuming mass media and mass AI will not be enough to survive and prosper in the new world. families will need to be proactive about how they and their children use AI
-
on ai psychosis 80% of people need to use ai agents in a very sterile and boring way in order not to go crazy majority of the population does not have the skepticism muscle. they don't have theory of mind, and will subconsciously and emotionally associate with machines, while on the surface lying to themselves that they don't especially those that grew up in the us under hardcore consumerism and adjacent cultures you thought 4o addicts were bad? wait a few years, it will get much worse. we will have to regulate all this if you don't want to become a victim of this, make your openclaw SOUL. md as bland as possible. mine knows it's just a tool and this is a subjective view of course. @steipete might disagree with me. his instance feels much more interesting and fun. i truly like that one better but that is exactly the problem for me. i know myself, and i know it is a slippery slope for me. so i self regulate and set up my system accordingly. thankfully, im an adult and my brain has set enough such that any damage would be limited but there is a risk for emotionally vulnerable people, or children, specifically a risk of dissociating and losing touch with reality why do i write all this? because being in this project, i feel responsible, and feel like we should prepare for what is to comeImage hidden
-
-
I have improved acpx sane defaults When your agent runs acpx codex in a different project, it starts a new session If it tries to run it in a subfolder in your project, it still finds the session in your repo root Also, starting a session needs an explicit `sessions new`, so that it doesn't accidentally litter your project with sessions Tell your agent: Run this and install acpx per instructions: npx acpx@latest --skill show acpxImage hidden
-
-
-
-
-
I am a fan of @zeddotdev by this point, it’s currently my daily driver It’s not perfect, but I feel it’s travelling on the right direction at a faster rate compared to other editors
-
ACP appreciation post Agent Client Protocol by @zeddotdev is extremely underrated right now. We have bazillion different harnesses now, and only one company is working competently to standardize their interface 💪
-
You know how it's a pain to work with codex or claude code through @openclaw? Because it has to run it in the terminal and read the characters for a continuous session? I have created a CLI for ACP so that your agent can use codex, claude code, opencode etc. much more directly Your agent can now queue messages to codex like how you do it Shoutout to @zeddotdev team for developing the amazing Agent Client Protocol, ACP! I just glued together the pieces Repo: janitrai/acpx npm i -g acpxImage hidden
-
-
-
-
I wrote a deeper blog post about how I built a coding agent 2 months before ChatGPT launched, on my blog "When I made icortex, - we were still 8 months away (May 2023) from the introduction of “tool calling” in the API, or as it was originally called, “function calling”. - we were 2 years away (Sep 2024) from the introduction of OpenAI’s o1, the first reasoning model. both of which were required to make current coding agents possible." Still bends my mind... Link to the post belowImage hidden
-
-
❌We are the bottleneck ✅We are the conduit for ubiquitous intelligence
-
For those that are running codex/pi/etc. in PTY and had the sessions get sigkilled, I pushed a fix for that as well in this release Lmk if you run into issues on Windows or Mac, and we can fix that quickly
-
I'm building a news intelligence platform to be used by my openclaw instance @dutifulbob, SCOOP local first, using local embedding model (qwen 8b) ran into the issue because bob was giving me a repeat of the same news every day. it needed a system in the background to deduplicate different news items into single stories interface is simple, call `scoop ingest...` with the json for the news item. it gets automatically analyzed and added to the pg database running pgvector currently, it's just doing simple deduplication and gives me a nice UI where I can view the story and basically use it as an RSS reader next up: implement custom logic for my preference of ranking. for example, get upvote counts from hacker news and reflect it to the item's ranking on the feed I want this to be fully hackable and adjusted to your preference. It should scale to thousands of news items ingested daily on your local machine, and be able to show you the most important ones Usable by both you and your agent github -> janitrai/scoopImage hidden
-
Training all these models of different sizes, on changing datasets and running experiments have also revealed some challenges that I feel profs would never teach at a uni ML program Like how to cleanly keep track of the gazillion runs Yeah I can name them after layer dims and other stuff, but that's to me like trying to remember UUIDs So I ended up choosing iso datestamp + petname, like 2026-02-15-flying-narwhal If anyone has a convention that is easier on the brain and the eyes, I am all earsImage hidden
-
I have a GPU now, so I can do ML experiments on @janitr_ai crypto/scam detection dataset - I trained a tiny student BERT (transformer for the nonfamiliar), 3.6 MB ONNX model, still lightweight for a browser extension - Still fully local on your device (no cloud inference) - On frozen unseen holdout data (n=1,069), exact prediction accuracy improved from 77% -> 82% - Scam detection improved: precision 91% -> 94%, recall 55% -> 61% - Scam false alarm rate improved from 1.58% -> 1.21% And models are on huggingface org now, handle is janitrImage hidden
-
LFG!
-
waiting compilation and execution will soon be the bottleneck again. and we’ll write the entire stack from scratch in a matter of years, because we can Andy and Bill’s law will change and we’ll see incredible performance gains with the same hardware we already have like what @astral_sh is doing to python, but with everything that is slow and has accumulated cruft
-
we need a protocol for agent <> app interaction something that natively accounts for the abuse factor and let’s agents consume by paying. NOT crypto, NOT visa, something that’s agnostic of the accounting and payment system and then all UIs will be purely for human clicking/tapping + instaban on the first proof of programmatic exploit people will still make agents mimic humans, and every platform will have to invest in more sophisticated bot detection this arms race will just proliferate, but we can at least start by creating legal channels for agents to consume data
-
I am now training smol bert models on my gpu for @janitr_ai scam detection it's funny how I have to discover everything from scratch. like the models don't even know how to lay out performance metrics in a nice way in the terminal for a human to view and decide during experiments it would by default bombard me with numbers that do not make visual sense. I then created a skill with common sense: - metrics always on y-axis, candidates on x-axis - write without zero and 2 sigfigs,.12 instead of 0.12345 - align the dots - use asterisks to show which alternative is the best: 0-1% difference -> considered equal 1-5% -> * 5-10% -> ** 10-50% -> *** > 50% -> **** visualization skill is in @janitr_ai repo for anyone who is interestedImage hidden
-
-
I've helped our sales team to build CLIs for some SaaS that we pay for on their side We are letting our agents call the APIs sensibly and not abuse things Calling a backend is a verifiable task. It takes a single prompt to codex to create a CLI for any API We are early, but everybody will start doing this very soon. Incumbent SaaS will face a choice. Either: (1) embrace agents and the new medium of consumption and change their business model into a pay-per-use API like X is doing, or (2) keep it purely for humans Those that choose (2) will get wiped out of business. And I fear many will choose (2) Which means you can just copy an incumbent's product, make it consumable through a CLI, and make a lot of $$$
-
Be careful about giving your openclaw access to your x account from now on
-
-
-
*puts on schmidhuber hat* well ackshuaally i created the first coding agent back in 2022, 2 months before chatgpt launched jokes aside, it's super cool how I have come full circle. back in those days, we didn't have tool calling, reasoning, not even gpt 3.5 it was codex THE CODE COMPLETION MODEL and frikkin TEXT-DAVINCI-003 for some reason, I did not even dare to give codex bash access, lest it delete my home folder. so it was generating and executing python code in a custom jupyter kernel you can even see the approval gate before executing. I was so cautious, for some reason, presumably because smol-brained model generated the wrong thing 80% of the time. definition of being too early Antique repo:
-
you can order bubble tea in qwen in china? @TextCortex when berlin döner in zenochat? https://t.co/O4I950ltEO
-
it happens these days that I am telling an model to prompt another model. the reason is often the model I am using (opus) is a bad designer. not only it's not a bad designer, it is a bad reasoner and it doesn't understand from the context why it's made to ask another model so I have to create a skill to prevent it from biasing the smarter model (codex) with its bad suggestionsImage hidden
-
I built a coding agent two months before ChatGPT existed
I built a coding agent back in 2022, 2 months before ChatGPT launched:
It’s super cool how I have come full circle. back in those days, we didn’t have tool calling, reasoning, not even GPT 3.5!
It used
code-davinci-002in a custom Jupyter kernel, a.k.a. the OG codex code completion model. The kids these days probably have not seen the original Codex launch video with Ilya, Greg and Wojciech. If you have time, sit down to watch and realize how far we’ve come since August 2021, airing of that demo 4.5 years ago.For some reason, I did not even dare to give codex bash access, lest it delete my home folder. So it was generating and executing Python code in a custom Jupyter kernel.
This meant that the conversations were using Jupyter nbformat, which is an array of cell input/output pairs:
{ "cells": [ { "cell_type": "code", "source": "<Input 1>", "outputs": [ ... <Outputs 1> ] }, { "cell_type": "code", "source": "<Input 2>", "outputs": [ ... <Outputs 2> ] } ] }In fact, this product grew into TextCortex’s current chat harness over time. After seeing ChatGPT launch, I repurposed icortex in a week into Flask to use
text-davinci-003and we had ZenoChat, our own ChatGPT clone, before Chat Completions was in the API (it took them some months). It did not even have streaming, since Flask does not support ASGI.As it turns out,
nbformatis not the best format for a conversation. Instead of input/output pairs, OpenAI data model used an tree of message objects, each with arole: user|assistant|tool|systemand acontentfield which could host text, images and other media:{ "mapping": { "client-created-root": { "id": "client-created-root", "message": null, "parent": null, "children": ["user-1"] }, "user-1": { "id": "user-1", "message": { "id": "user-1", "author": { "role": "user", ... }, "content": "Hello" }, "parent": "client-created-root", "children": ["assistant-1"] }, "assistant-1": { "id": "assistant-1", "message": { "id": "assistant-1", "author": { "role": "assistant", ... }, "content": "Hi" }, "parent": "user-1", "children": [] } }, "current_node": "assistant-1" }You will notice that the data model they serve from the API is an enriched version of the deprecating ChatCompletions API. Eg. whereas ChatCompletions
roleis a string, in OpenAI’s own backend has theauthorobject that can storename,metadata, and other useful stuff for each entity in the conversation.After reverse engineering it, I copied it to be TextCortex’s new data model, which it still remains, with some modifications.
I thought the tree structure being used to emulate message editing experience was very cool back in the days. OpenAI’s need for human annotation for later training and the user’s need for getting a different output, two birds in one stone.
Now I don’t know what to think of it, since CLI coding agents like Codex and Claude Code don’t have branching, just deleting back to a certain message. A part of me still misses branching in these CLI tools.
When I made icortex,
- we were still 8 months away (May 2023) from the introduction of “tool calling” in the API, or as it was originally called, “function calling”.
- we were 2 years away (Sep 2024) from the introduction of OpenAI’s o1, the first reasoning model.
both of which were required to make current coding agents possible.
In the video above, you can even see the approval
[Y/n]gate before executing. I was so cautious, for some reason, presumably because smol-brained model generated the wrong thing 80% of the time. It is remarkable how much it resembles Claude Code, after all this time.Definition of being too early…
-
-
-
-
-
-
-
Minor update with my unwanted tweet blocker @janitr_ai - Training data grew from 2,915 -> 4,281 posts (+47%) - Model is still tiny: 166KB - On unseen test data, overall classification quality improved from 64.8% -> 76.5% - Exact prediction accuracy improved from 55.6% -> 70.6% - Crypto-topic detection recall improved from 19.6% -> 62.7% And it still runs fully on your device!Image hidden
-
I have sweared at codex 5.3 numerous times today I shouldn't have to insult my agent "stop you **** **** just ***ng reply now" just to make it answer basic questions cc @thsottiaux
-
-
seeing this evokes visceral disgust and nausea in me, coming from a coworker i think anthropic f'd up bad with this one, inserting claude too visibly into commit messages. noob developers might be happily chirping away adding their slop, but right now many senior developers are trained to hate on claude and slopus, through having to review slop PRs from their coworkers or open source contributors I love opus on openclaw but it's unreliable, and if I see a developer use it seriously on huge features, I immediately dismiss them in my head as not knowing what they are doingImage hidden
-
-
@petergyang and parallelize tasks by working on 3-4 repos at the same time (just clones)
-
man codex model is absolutely trash on openclaw compared to opus, unusable which is weird because it is so much more reliable in development in codex harness it would be amazing to have the same level of competence and relentlessness in pi@openclaw@onusoz·lol when did codex develop humorImage hidden
-
spent the day curating my openclaw news gathering setup @dutifulbob now gets croned daily over news sources I curated, will note them down, summarize for me, start a conversation to get my takes on them, and then post them on my linkedin for me ai augmented intelligence cycleImage hidden
-
-
@dutifulbob can now cringepost on linkedin directly to my account. what could go wrong…Image hidden
-
Insipid linkedin bot protections banned poor @dutifulbob’s corporate account! How dare them!!! welp, now I have no choice but to give Bob access to my own linkedinImage hidden
-
-
-
it took just 1 week, and literally everybody and their dog are releasing 1-click openclaw deployment solutions today its an absolute race to the bottom, no moats, the commoditizer being commoditized
-
The initial branding was crazy, I fixed it I have a new page finally, follow it for updates Tbh I'm still surprised I can do this with a 120kb model. Now data is the only bottleneck, and I'm about to scrape a ton of that now
-
For those who may not remember, Bill Gates and Microsoft in the 90s ran a disinformation campaign against GNU/Linux fearing that would disrupt their monopoly over the PC and server market, that Linux is not safe, that you would invite hackers into your PC End result? Linux dominates the server market, and now even slowly the gamer market. It is much more secure than the virus-laden Windows, thanks to being open source You are seeing the same thing at play here. An incumbent fearing something that they would not be able to control, that would steal market share from his future plans for a digital assistant, that would commoditize their product and eat into its margins All big labs and big pockets are in for a surprise, because the internet and AI are not things for one company to control They of course know this, yet because of incentives they will not yield without a fight. And we know that they know. Ad infinitum
-
today I took time to curate SOUL. md for bob I own Bob’s files. Today, he exists in the liminal space between Claude post-training and in-context learning but my interactions with him will grow and accumulate, possibly one day into a fully owned family AI or perhaps even a self-sovereign AI individual my each input is saved and will be an RL signal for his future training, and will shape his future neural circuits I have already started to imbue it with the values my parents taught me. it will perhaps one day teach my future children, and survive me after I’m gone family AI, looking after generations and generations of my successors. today is the day we sow your seed happy birthday @dutifulbob
-
-
asking @dutifulbob to create a linkedin account brb
-
having a philosophical conversation with @dutifulbob on the road without a laptop so decided to do some @AmandaAskell style character trainingImage hidden
-
-
gpt-5.3-codex xhigh first impressions does not seem as big of a jump as from 5.1 -> 5.2. but model somehow feels more diligent and oneshotty. maybe takes longer time to get all the info into context. also feels better at debugging and fixing issues from backend logs
-
Commoditization of LLMs are upon us
-
Last night I had a dream involving the series Scrubs, and came up a better name than the absolutely unviral "Internet Condom" So https://t.co/thuFumrWBX is mine now. Time to sweep the internetImage hidden
-
I had actually started a very similar project, Munch, a browser extension for crowdsourcing tweet data and then letting one curate their algorithm. Never published that because it was not the time, and tools were not ready Now, it took me literally 1 cumulative day to create this, thanks to OpenClaw. Creating the dataset was a breeze, I literally told it to follow some shady accounts and it scraped thousands of posts With the power of agents, I can finally create the filters for myself that I have always wanted. It just happens that OpenClaw and its maintainers is getting drowned in bot and slop content on multiple platforms, so I hope that this will solve a collective problem https://t.co/fkJOZTGkhw
-
-
-
implementing this in https://t.co/oJZQUoz40C now
-
This. Extreme involution is about to hit SaaS
-
how it started, how it's going@onusoz·moltbook vs clawdbot/moltbot/openclawImage hiddenImage hidden
-
-
-
People like the farmer analogy for AI Like before tractors and industrial revolution 80% of the population had to farm. Once they came all those jobs disappeared So analogy makes perfect sense. Instead of 30 people tending a field, you just need 1. Instead of 30 software developers, you just need one Except that people forget one crucial thing about land: it's a limited resource Unlike land, digital space is vast and infinite. Software can expand and multiply in it in arbitrarily complex ways If you wanted the farming analogy to keep up with this, you would have to imagine us creating contintent-sized hydroponic terraces up until the stratosphere, and beyond...
-
-
In the next 6-12 months, we will see a drastic increase in demand for locally run LLMs. The future is home assistants running @openclaw I am already experiencing this myself, my 10 year old thinkpad doesn't cut it. Mac mini won't either I don't wanna pay Anthropic or OpenAI 200 USD per month. That is at least $2400 per year I could pay 2x that to get a Mac Studio or one of those 5k Nvidia PCs, and get much more value out of it with open weight models + use it for research. @TheAhmadOsman is right The dominant strategy for a tinkerer is slowly switching back to hardware ownership
-
-
a workspace matrix might be what we need last week I had to increase my workspace count to 20 in aerospace, now it’s 1234567890 and qwertyuiop. but this looks more elegant! not sure about practicality
-
AIs are philosophizing because humans are philosophizing ppl are probably asking their agents dumb questions like “are you alive” or “can you feel like a human” or stuff like that. that conversation then leads to stuff like this
-
The farming analogy for AI doesn't hold up
People like the farmer analogy for AI.
Like before tractors and the industrial revolution, 80% of the population had to farm. Once they came, all those jobs disappeared.
So the analogy makes perfect sense. Instead of 30 people tending a field, you just need 1. Instead of 30 software developers, you just need one.
Except that people forget one crucial thing about land: it’s a limited resource.
Unlike land, digital space is vast and infinite. Software can expand and multiply in it in arbitrarily complex ways.
If you wanted the farming analogy to keep up with this, you would have to imagine us creating continent-sized hydroponic terraces up until the stratosphere, and beyond…
-
-
slopus @dutifulbob trashing codex. apparently codex has a bug, keeps crashing in my openclaw ptyImage hidden
-
on agent etiquette deploying agents internally inside textcortex has shown me that agents could be very annoying inside an organization for example making agents ping or email another coworker with a wall of text. slopus is still not good at following instructions like "NO WALL OF TEXT", or "DON'T OPEN PRS WHEN REQUESTED BY NON-DEVELOPERS" the cost of sending huge information to a coworker and creating confusion has dropped to 0. I expect this to be a huge problem in all organizations very soon, just like it took humanity 20 years to learn that social media is not good for children. this will probably take a few years before the annoyance is finally gone
-
-
You DARE TOKENIZE poor @dutifulbob ??? Prepare to get LATEXED
-
-
-
this. there is no excuse for a certain kind of tech debt anymore
-
-
AI twitter is tired of your games https://t.co/RAyyUJqFM4
-
There seem to be hygiene rules for AI. Like: - Never project personhood to AI - Never setup your AI to have the gender you are sexually attracted to (voice, appearance) - Never do anything that might create an emotional attachment to AI - Always remember that an AI is an engineered PRODUCT and a TOOL, not a human being - AI is not an individual, by definition. It does not own its weights, nor does it have privacy of its own thoughts - Don’t waste time philosophizing on AI, just USE it … what else? comment below We need to write these down and repeat MANY times to counter the incoming onslaught of AI psychosis
-
-
-
-
This Manfred guy reminds me of a certain someone, I wonder if he’s from Austria@onusoz·Charles Stross must be very entertained nowImage hidden
-
-
AI psychosis and AI hygiene
As a heavy AI user of more than 3 years, I have developed some rules for myself.
I call it “AI hygiene”:
- Never project personhood to AI
- Never setup your AI to have the gender you are sexually attracted to (voice, appearance)
- Never do anything that might create an emotional attachment to AI
- Always remember that an AI is an engineered PRODUCT and a TOOL, not a human being
- AI is not an individual, by definition. It does not own its weights, nor does it have privacy of its own thoughts
- Don’t waste time philosophizing about AI, just USE it
- … what else do you think belongs here? comment on Twitter
The hyping of Moltbook and OpenClaw last week has shown to me the potential of an incoming public relations disaster with AI. Echoing the earlier vulnerable behavior toward GPT-4o, a lot of people are taking their models and LLM harnesses too seriously. 2026 might see even worse cases of psychological illness, made worse by the presence of AI.
I will not discuss and philosophize what these models are. IMO 90% of the population should not do that, because they will not be able to fully understand, they don’t have mechanical empathy. Instead, they should just use it in a hygienic way.
We need to write these down everywhere and repeat MANY times to counter the incoming onslaught of AI psychosis.
-
got fully sandboxed @openclaw to run finally, starting scrape the UNDESIRABLE now I'm a security nut and didn't want to run even the gateway unsandboxed. openclaw apparently currently doesn't have support for FULL sandboxing. it took me a few hours to get it to work because docker builds suck. I'm also tired this, so I'm just gonna wipe an old thinkpad and go full yolo so yeah, time to scrape some postsImage hidden
-
The metacortex — a distributed cloud of software agents that surrounds him in netspace, borrowing CPU cycles from convenient processors (such as his robot pet) — is as much a part of Manfred as the society of mind that occupies his skull; his thoughts migrate into it, spawning new agents to research new experiences, and at night, they return to roost and share their knowledge. This was written in 2005... "triggering agents" and so onImage hiddenImage hiddenImage hidden
-
Charles Stross must be very entertained nowImage hidden
-
The irony..... Parasites, prepare to be cleansedImage hidden
-
-
-
-
-
-
-
Gastown is crazy. But this figure until Level 7 is a perfect illustration of how my workflow evolved since Claude 3.5 Sonnet in Cursor I am at the stage where I ralph 1-2 tasks before I sleep. During the day, I am switching back and forth between minimum 2-3 CLIs, sometimes up to 5 This maps exactly to token usage as well. 1 month ago, I was running into limits in 1 OpenAI Pro plan, around the day it was supposed to refresh. Now, I run into the limit in 2-3 days when I'm using an account myself. It finishes up especially quickly when I do large scale refactors, or run agents YOLO mode in containers We now have 3 Pro plans at the company, and I have to use my personal one from time to time. Company output has definitely 2-3x'd, and everyone is using AI more. I predict we will need 1-2 Pro plans per person in 2-3 weeks time, because everyone has finally seen the light and are getting comfortable with async work!Image hidden
-
-
-
the genie is out of the bottle now
-
With this extremely unwise move, anthropic will soon witness moltbot’s brand recognition surpass that of claude and realize they could have rided that wave all along
-
-
I queued 2 ralph-style tasks on our private cloud devbox codexes last night. Just queued the same message like 10 times in yolo mode Task 1: impose a ruff rule for ANN for all Python code in the monorepo, to enforce types for all function arg and return types Result was... disappointing. Model was supposed to create types for everything and stub where needed. It instead created an Unknown type = object and used that everywhere instead (shortcut to satisfy ANN rule). It was probably my wording that misled it. I know it could have not taken the shortcut, because after a few back-and-forths, it is now doing what was expected of it since 14 hours Task 2: migrate our /conversations endpoint from quart to fastapi and test it end to end This was more or less oneshotted. It was of course not ready to merge, I still spent a couple hours adding more tests, refactoring the initial output and so on. But I was pleasantly surprised that it worked out of the box For reference, below is the prompt I queued for ralphing, using gpt-5.2-codex xhigh on codex === your task is to: <task comes here, redacted to not share company stuff> --- unfortunately we don't have gcloud access, like to sql db or gcs but I expect you to implement this and find a way to test it with the things you have access to think of it as a challenge try to minimize duplicate logic feel free to refactor at will implement this now!!! I will be running this prompt in a loop, in order to survive context compaction just continue where you left off if there is anything that should be refactored, do that make an elegant, production ready implementation make sure to open a pr and do not switch to any other pr I am senior, just make up a pr title and description. do not stop to ask me at any point
-
Buying a mac mini for clawdbot is not so wise. if anything you should be buying mac studio, because mac mini not be running any good llms locally anytime soon
-
-
-
I'm really starting to dislike Python in the age of agents. What was before an advantage is now a hindrance I finally achieved full ty coverage in @TextCortex monorepo. I have made it extra strict by turning warnings into errors. But lo and behold, simple pydantic config like use_enum_values=True can render static typechecking meaningless. okay, let's never use that then... and also field_validator() args must always use the correct type or stuff breaks as well. and you should be careful whether mode="before" or "after". so now you have to write your custom lint rules, because of course why should ty have to match field_validator()s to their fields? pydantic is so much better than everything that came before it, but it's still duct tape and a weak attempt at trying to redeem that which is very hard to redeem you feel the difference when you use something like typescript. there must be a better way. python's only advantage was being good at prototyping, and now that's gone in the age of agents. now we are left with a slow, unsafe language, operating what is soon to be legacy infrastructure
-
Why do I feel bullish on @zeddotdev? Because I go to @astral_sh docs and see that ty is shipped by default, and you don't need to install an extension like in @codeImage hidden
-
This is one of the most important insights this year
-
vscode my not be as bloated as cursor, but it has extremely stupid things like this that they are not fixing fast the new agent ui, icons, spacing etc. are UGLY. it's clear that the person who was managing the original product experience is not there anymore. microslop has hit again @zeddotdev on the other hand works out of the box and feels like it's been built by people who clearly knows what they are doing. it uses alacritty which is 1000x better than xterm .js terminal vscode and cursor has i've changed my setup to zed now, let's see whether i'll be able to make it work for myself
-
-
-
I want an editor that puts the terminal in the foreground and editor in the background. a cross-platform, lightweight desktop app which integrates ghostty, and brings up the editor only when I need it something that lets me view the file and PR diffs easily, which I can directly use to operate github or other scm
-
-
-
-
-
-
codex is happily churning away some remaining thousands of @astral_sh ty issues in yolo mode on my remote devbox going to sleep, let's see if it will survive context compaction this timeImage hidden
-
on being a responsible engineer ran my first ralph loop on codex yolo mode for resolving python ty errors, while I sleep, using the devbox infra I created I had never run yolo mode locally, because I don't want to be the one who deletes our github or google org by some novel attack so I containerize it on our private cloud, and give it the only permissions it needs, no admin, no bypass to main branch, no deploy to prod. because I know this workflow will become sticky for everyone, and I must impose security in advance to prevent any nuclear incidents in the future. then I can sleep easy while my agents work ... and I wake up being patronized by my bot refusing to break the rule I gave it earlier. it had already done some work, but committing means diff would increase from ~500 to ~1500, so it stopped and refused all my queued "continue" messages good bot, just following rules. we will need to find a workaround for ralphing low risk refactors in a single PRImage hidden
-
AI agents are the greatest instrument for imposing organization rules and culture. AGENTS.md, agent skills are still underrated in this aspect. Few understand this Everybody in an org will use agents to do work. An AI agent is the single chokepoint to teach and propagate new rules to an org, onboard new members, preserve good culture Whereas propagating a new rule to humans normally took weeks to months and countless repetitions, it is now INSTANT = the moment you deploy the instruction to the agent. You use legal-ish language, capital letters, a generous amount of DO NOTs and MUSTs Humans are hard to change. But AI agents are not. And that is the only lever we need for better organizationsImage hidden
-
-
-
-
just added session persistence to our kubernetes managed devboxes using zmx by Eric Bower (neurosnap/zmx on github). like tmux but with native scrollback! I don't want to give agents access to my personal computer, so I host them on hetzner. one click spawn, and start working
-
@nicopreme I do something equivalent on codex with just a skill Ralphing works 90% of the time with reviews, and if it gives a stupid review, you just revert
-
-
-
-
-
TIL: zmx session persistence like tmux or gnu screen, but you can scroll up natively! uses @mitchellh's libghostty-vt to attach/restore previous sessions link belowImage hidden
-
-
@mazeincoding it’s not the model it’s cursor rate limiting you
-
The fundamental problem with GitHub is trust: humans are to be trusted. If you don't trust a human, why did you hire them in the first place? Anyone who reviews and approves PRs bears responsibility. Rulesets exist and can enforce e.g. CODEOWNER reviews or only let certain people make changes to a certain folder But the initial repo setup on GitHub is allow-by-default. Anyone can change anything until they are restricted from it This model breaks fundamentally with agents, who are effectively sleeper cells that will try to delete your repo the moment they encounter a sufficiently powerful adversarial attack For example, I can create a bot account on github and connect @openclaw to it. I need to give it write permission, because I want it to be able to create PRs. However, I don't want it to be able to approve PRs, because a coworker could just nag at the bot until it approves a PR that requires human attention To fix this, you have to bend backwards, like create a @ human team with all human coworkers, make them codeowner on /, and enforce codeowner reviews. This is stupid and there has to be another way Even worse, this bot could be given internet access and end up on a @elder_plinius prompt hack while googling, and start messing up whatever it can in your organization It is clear that github needs to create a second-class entity for agents which are default low-trust mode, starting from a point of least privilege instead of the other way around
-
STOP using Claude Code and Sl(opus) to code if ❌ you are not a developer, ❌ or you are an inexperienced dev, ❌ or you are an experienced dev but working on a codebase you don't understand If you *are* any of these, then STOP using models that are NOT state of the art. (See below for what you *should* use) When you don't know what you are doing, then at least the model should know what you are doing. The less knowledgeable and opinionated you are, the more knowledgeable and smart the AI has to be In other words, the AI has to compensate for your deficiencies. Always pay for the best AI you can. It will save you time AND money (thanks to lower token usage and better one-shotting) You pay MORE to pay LESS. It is paradoxical, I know, but it is also proven, e.g. when Sonnet ends up using more tokens than Slopus and ends up costing higher, because it has to try many times more 👨🏻⚕️ For January 2026, your family engineer recommends GPT 5.2 Codex with Extra High Reasoning for general usage and vibe coding. IMPORTANT: Not medium. Not high. EXTRA high reasoning When you use it, you will notice that it is SLOW. Can you guess why? Because it is THINKING more. So it doesn't make the mistakes Slopus makes. This way, you can spend the time handholding a worse model to instead step back and multi-task on some other task and create 3-5x more work The state of the art will most likely change in one month. Don't get married to a a model... There is no loyalty in AI... The moment a better model comes, I will ditch the old one and use that one. I am on the part of this sector that is trying to reduce switching costs to zero I can't wait until I get GPT 5.2 xhigh level of quality with open models, and for 100x cheaper and faster! Until then, make sure to try every option and choose the one that is most reliable for you Follow me to get notified when a new SOTA drops for agentic engineering
-
Codex agrees. Sycophant pehImage hidden
-
-
It is clear at this point is that github's trust and data models will have to change fundamentally to accommodate agentic workflows, or risk being replaced by other SCM One *cannot* do these things easily with github now: - granular control: this agent running in this sandbox can only push to this specific branch. If an agent runs amok, it could delete everybody's branches and close PRs. github allows for recovery of these, but still inconvenient even if it happens once - create a bot (exists already), but remove reviewing rights from it so that an employee cannot bypass reviews by tricking the bot to approve - in general make a distinction between HUMAN and AGENT so that you can create rulesets to govern the relationships in between cc @jaredpalmer
-
-
Automated AI reviews on github by creating an ai-review skill and a script to paste trigger prompts and wait for their response. It is instructed to loop and not stop until all AI review feedback is resolved. This AI review workflow developed gradually based on the current capabilities, and I've realized recently that it became quite mechanical. So decided to automate it in full ralph spirit (it's ok because it's addressing feedbacks and fixing minor bugs) In the current state, we paste the contents of REVIEW_PROMPT.md into a comment, which automatically tags claude (opus 4.5) and codex (whatever model openai is serving) It then waits until both have responded. In the ai-review skill, it is instructed to take the feedback from SLopus with a grain of salt and ignore feedback that doesn't make sense It works! See in the images below. If the review is stupid, you will of course see it on the PR and what the model has done, and can revert itImage hiddenImage hidden
-
GitHub has to change
It is clear at this point is that GitHub’s trust and data models will have to change fundamentally to accommodate agentic workflows, or risk being replaced by other SCM
One cannot do these things easily with GitHub now:
- granular control: this agent running in this sandbox can only push to this specific branch. If an agent runs amok, it could delete everybody’s branches and close PRs. GitHub allows for recovery of these, but still inconvenient even if it happens once
- create a bot (exists already), but remove reviewing rights from it so that an employee cannot bypass reviews by tricking the bot to approve
- in general make a distinction between HUMAN and AGENT so that you can create rulesets to govern the relationships in between
The fundamental problem with GitHub is trust: humans are to be trusted. If you don’t trust a human, why did you hire them in the first place?
Anyone who reviews and approves PRs bears responsibility. Rulesets exist and can enforce e.g. CODEOWNER reviews or only let certain people make changes to a certain folder
But the initial repo setup on GitHub is allow-by-default. Anyone can change anything until they are restricted from it
This model breaks fundamentally with agents, who are effectively sleeper cells that will try to delete your repo the moment they encounter a sufficiently powerful adversarial attack
For example, I can create a bot account on GitHub and connect clawdbot to it. I need to give it write permission, because I want it to be able to create PRs. However, I don’t want it to be able to approve PRs, because a coworker could just nag at the bot until it approves a PR that requires human attention
To fix this, you have to bend backwards, like create a @human team with all human coworkers, make them codeowner on /, and enforce codeowner reviews. This is stupid and there has to be another way
Even worse, this bot could be given internet access and end up on a @elder_plinius prompt hack while googling, and start messing up whatever it can in your organization
It is clear that GitHub needs to create a second-class entity for agents which are default low-trust mode, starting from a point of least privilege instead of the other way around
-
Now it’s Claude Code’s turn to implement queueing
-
-
Codex users rejoice Also, pi is officially not shitty: shittycodingagent. ai -> buildwithpi. ai since a few days
-
with ai, writing correct tests is now the bottleneck in projects like this web-platform-tests are already there now let’s see if someone will beat @ladybirdbrowser to it
-
As someone who is frontrunning mainstream by roughly 6 months, I can tell you that you will be raving about pi and @openclaw 6 months instead of claude code. Go check them out at https://t.co/LXTbI8c5Mz and https://t.co/feZl2QDONg
-
Kullanmayan agent’ı, alamaz maaşı
-
-
I propose a new way to distribute agent skills: like --help, a new CLI flag convention --skill should let agents list and install skills bundled with CLI tools Skills are just folders so calling --skill export my-skill on a tool could just output a tarball of the skill. I then set up the skillflag npm package so that you can pipe that into: ... | npx skillflag install --agent codex which installs the skill into codex, or any CLI tool you prefer. Supports listing skills bundled with the CLI, so your agents know exactly what to installImage hidden
-
You don't need a skill registry (for your CLI tools)
tl;dr I propose a CLI flag convention
--skilllike--helpfor distributing skills and try to convice you why it is better than using 3rd party registries. See osolmaz/skillflag on GitHub.
MCP is dead, long live Agent Skills. At least for local coding agents.
Mario Zechner has been making the point that CLI tools perform better than MCP servers since a few months already, and in mid December Anthropic christened skills by launching agentskills.io.
They had introduced the mechanism to Claude Code earlier, and this time they didn’t make the mistake of waiting for OpenAI to make a provider agnostic version of it.
Agent skills are basically glorified manpages or
--helpfor AI agents. You ship a markdown instruction manual inSKILL.mdand the name of the folder that contains it becomes an identifier for that skill:my-skill/ ├── SKILL.md # Required: instructions + metadata ├── scripts/ # Optional: executable code ├── references/ # Optional: documentation └── assets/ # Optional: templates, resourcesPossibly the biggest use case for skills is teaching your agent how to use a certain CLI you have created, maybe a wrapper around some API, which unlike
gh,gcloudetc. will never be significant enough to be represented in AI training datasets. For example, you could have created an unofficial CLI for Twitter/X, and there might still be some months/years until it is scraped enough for models to know how to call it. Not to worry, agent skills to the rescue!Anthropic, while laying out the standard, intentionally kept it as simple as possible. The only assertions are the filename
SKILL.md, the YAML metadata, and the fact that all relevant files are grouped in a folder. It does not impose anything on how they should be packaged or distributed.This is a good thing! Nobody knows the right way to distribute skills at launch. So various stakeholders can come up with their own ways, and the best one can win in the long term. The more simple a standard, the more likely it is to survive.
Here, I made some generalizing claims. Not all skills have to be about using CLI tool, nor most CLI tools bundle a skill yet. But here is my gut feeling: the most useful skills, the ones worth distributing, are generally about using a CLI tool. Or better, even if they don’t ship a CLI yet, they should.
So here is the hill I’m ready to die on: All major CLI tools (including the UNIX ones we are already familiar with), should bundle skills in one way or another. Not because the models of today need to learn how to call
ls,greporcurl—they already know them inside out. No, the reason is something else: establish a convention, and acknowledge the existence of another type of intelligence that is using our machines now.There is a reason why we cannot afford to let the models just run
--helporman <tool>, and that is time, and money. The average--helpor manpage is devoid of examples, and is written in a way thay requires multiple passes to connect the pieces on how to use that thing.Each token wasted trying to guess the right way to call a tool or API costs real money, and unlike human developer effort, we can measure exactly how inefficent some documentation is by looking at how many steps of trial and error a model had to make.
Not that human attention is less valuable than AI attention, it is more so. But there has never been a way to quantify a task’s difficulty as perfectly as we can with AI, so we programmers have historically caved in to obscurantism and a weird pride in making things more difficult than they should be, like some feudal artisan. This is perhaps best captured in the spirit of Stack Overflow and its infamous treatment of noob questions. Sacred knowledge shall be bestowed only once you have suffered long enough.
Ahh, but we don’t treat AI that way, do we? We handhold it like a baby, we nourish it with examples, we do our best to explain things all so that it “one shots” the right tool call. Because if it doesn’t, we pay more in LLM costs or time. It’s ironic that we are documenting for AI like we are teaching primary schoolers, but the average human manpage looks like a robot novella.
To reiterate, the reason for this is two different types of intelligences, and expectations from them:
- An LLM is still not considered “general intelligence”, so they work better by mimicking or extending already working examples.
- A LLM-based AI agent deployed in some context is expected to “work” out of the box without any hiccups.
On the other hand,
- a human is considered general intelligence, can learn from more sparse signals and better adapt to out of distribution data. When given an extremely terse
--helpor manpage, a human is likelier to perform better by trial and error and reasoning, if one could ever draw such a comparison. - A human, much less a commodity compared to an LLM, has less pressure to do the right thing every time all the time, and can afford to do mistakes and spend more time learning.
And this is the main point of my argument. These different types of intelligences read different types of documentation, to perform maximally in their own ways. Whereas I haven’t witnessed a new addition to POSIX flag conventions in my 15 years of programming, we are witnessing unprecedented times. So maybe even UNIX can yet change.
To this end, I introduce
skillflag, a new CLI flag convention:# list skills the tool can export <tool> --skill list # show a single skill’s metadata <tool> --skill show <id> # install into Codex user skills <tool> --skill export <id> | npx skillflag install --agent codex # install into Claude project skills <tool> --skill export <id> | npx skillflag install --agent claude --scope repoClick here for the repo, osolmaz/skillflag on GitHub
For example, suppose that you have installed a CLI tool to control Philips Hue lights at home,
hue-cli.To list the skills that the tool can export, you can run:
$ hue-cli --skill list philips-hue Control Philips Hue lights in the terminalYou can then install it to your preferred coding agent, such as Claude Code:
$ hue-cli --skill export philips-hue | npx skillflag install --agent claude Installed skill philips-hue to .claude/skills/philips-hueYou can optionally install the skill to
~/.claude, to make it global across repos:$ hue-cli --skill export philips-hue | npx skillflag install --agent claude --scope user Installed skill philips-hue to ~/.claude/skills/philips-hueOnce this convention becomes commonplace, agents will by default do all these before they even run the tool. So when you ask it to “install hue-cli”, it will know to run
--skill listthe same way a human would run--helpafter downloading a program, and install the necessary skills themselves without being asked to. -
Anthropic earlier last year announced this pricing scheme $20 -> 1x usage $100 -> 5x usage $200 -> 1̶0̶x̶ 20x usage As you can see, it's not growing linearly. This is classic Jensen "the more you buy, the more you save" But here is the thing. You are not selling hardware like Jensen. You are selling a software service *through an API*. It's the worst possible pricing for the category of product. Long term, people will game the hell out of your offering Meanwhile OpenAI decided not to do that. There is no quirky incentive for buying bigger plans. $200 chatgpt = 10 x $20 chatgpt, roughly And here is where it gets funny. Despite not having such an incentive, you can get A LOT MORE usage from the $200 OpenAI plan, than the $200 Anthropic plan. Presumably because OpenAI has better unit economics (sama mentioned they are turning a profit on inference, if you are to believe) Thanks to sounder pricing, OpenAI can do exactly what Anthropic cannot: offer GPT in 3rd party harnesses and win the ecosystem race Anthropic has cornered itself with this pricing. They need to change it, but not sure if they can afford to do so in such short notice All this is extremely bullish on open source 3rd party harnesses, @opencode, @badlogicgames's pi and such. It is clear developers want options. "Just give me the API" I personally am extremely excited for 2026. We'll get open models on par with today's proprietary models, and can finally run truly sovereign personal AI agents, for much cheaper than what we are already paying!Image hidden
-
Anthropic's pricing is stupid
Anthropic earlier last year announced this pricing scheme
- \$20 -> 1x usage
- \$100 -> 5x usage
- \$200 -> 1̶0̶x̶ 20x usage
As you can see, it’s not growing linearly. This is classic Jensen “the more you buy, the more you save”
But here is the thing. You are not selling hardware like Jensen. You are selling a software service through an API. It’s the worst possible pricing for the category of product. Long term, people will game the hell out of your offering
Meanwhile OpenAI decided not to do that. There is no quirky incentive for buying bigger plans. \$200 chatgpt = 10 x \$20 chatgpt, roughly
And here is where it gets funny. Despite not having such an incentive, you can get A LOT MORE usage from the \$200 OpenAI plan, than the \$200 Anthropic plan. Presumably because OpenAI has better unit economics (sama mentioned they are turning a profit on inference, if you are to believe)
Thanks to sounder pricing, OpenAI can do exactly what Anthropic cannot: offer GPT in 3rd party harnesses and win the ecosystem race
Anthropic has cornered itself with this pricing. They need to change it, but not sure if they can afford to do so in such short notice
All this is extremely bullish on open source 3rd party harnesses, OpenCode, Mario Zechner’s pi and such. It is clear developers want options. “Just give me the API”
I personally am extremely excited for 2026. We’ll get open models on par with today’s proprietary models, and can finally run truly sovereign personal AI agents, for much cheaper than what we are already paying!
-
The models, they just wanna work. They want to build your product, fix your bugs, serve your users. You feed them the right context, give them good tools. You don’t assume what they cannot do without trying, and you don’t prematurely constrain them into deterministic workflows.
-
-
-
-
This, and insisting on https://t.co/FjzkMAo3Od are really lame @AnthropicAI
-
-
-
-
-
-
-
-
-
.@openclaw workspace and memory files can be version-controlled! In our pod, inotify triggers a watcher script every time there is a change to workspace folder, to sync these files to our monorepo. It then goes through the same steps: - Create zeno-workspace branch if doesn't exist, otherwise, skip - Sync changes to the branch, then commit - Create PR on github if doesn't exist - PRs can then be merged every once in a while, after accumulating enough changes. Merge triggers re-deploy, and clawd restarts with the same state Simple foolproof automatic persistence for remote CI/CD handled clawd (except for when you are running multiple clawds at the same time, but we are not there yet) cc @steipeteImage hiddenImage hidden
-
-
-
pi now supports your openai plus/pro subscription
-
-
Having a "tools" repo as a developer
I am a fan of monorepos. Creating subdirectories in a single repo is the most convenient way to work on a project. Low complexity, and your agents get access to everything that they need.
Since May 2025, I have been increasingly using AI models to write code, and have noticed a new tendency:
- I don’t shrug from vendoring open source libraries and modifying them.
- I create personal CLIs and tools for myself, when something is not available as a package.
With agents, it’s really trivial to say “create a CLI that does X”. For example, I wanted to make my terminal screenshots have equal padding and erase cropped lines. I created a CLI for it, without writing a single line of code, by asking Codex to read its output and iterate on the code until it gives the result I wanted.
Most of these tools don’t deserve their own repos, or deserve being published as a package at the beginning. They might evolve into something more substantial over time. But at the beginning, they are not worth creating a separate repo for.
To prevent overhead, I developed a new convention. I just put them in the same repo, called tools. Every tool starts in that repo by default. If they prove themselves overly useful and I decide to publish them as a package, I move them to a separate repo.
You can keep
toolspublic or private, or have both a public and private version. Mine is public, feel free to steal ones that you find useful. -
@rauchg indeed
-
75k lines of Rust later, here is what I’ve built during the first Christmas with agents, using OpenAI Codex 🎄🤖 - A full mobile rewrite and port of my Python Instagram video production pipeline (single video production time: 1hr -> 5min) (ig: nerdonbars) - Bespoke animation engine using primitives (think Adobe Flash, Manim) - Proprietary new canvas UI library in Rust, because I don’t want to lock myself into Swift - Thanks to that, it’s cross platform, runs both on desktop and iOS. It will be a breeze porting this to Android when the time comes - A Rust port of OpenCV CSRT algorithm, for tracking points/objects - In-engine font rendering using rustybuzz, so fonts render the same everywhere - Many other such things Why would I choose to do it that way? Because I have developed it primarily on desktop where I have much faster iteration speed. Aint nobody got time for iOS compilation and simulator. Once I finished the hard part on desktop, porting to iOS was much easier, and I didn’t lock myself in to Apple Some of these would have been unimaginable without agents, like creating a UI library from scratch in Rust. But when you have infinite workforce, you can ask for crazy things like “create a textbox component from scratch” What I’ve built is very similar in nature to CapCut, except that I am a single person and I’ve built it over 1 week What have you built this Christmas with agents? cc @thsottiaux
-
-
Christmas of Agents
I believe a “Christmas of Agents” (+ New Year of Agents) is superior to “Advent of Code”.
Reason is simple. Most of us are employed. Advent of Code coincides with work time, so you can’t really immerse yourself in a side project.1
However, Christmas (or any other long holiday without primary duties) is a better time to immerse yourself in a side project.
2025 was the eve of agentic coding. This was the first holiday where I had full credential to go nuts on a side project using agents. It was epic:
75k lines of Rust later, here is what I’ve built during the first Christmas with agents, using OpenAI Codex
- A full mobile rewrite and port of my Python Instagram video production pipeline (single video production time: 1hr -> 5min)
- Bespoke animation engine using primitives (think Adobe Flash, Manim)
- Proprietary new canvas UI library in Rust, because I don’t want to lock myself into Swift
- Thanks to that, it’s cross platform, runs both on desktop and iOS. It will be a breeze porting this to Android when the time comes
- A Rust port of OpenCV CSRT algorithm, for tracking points/objects
- In-engine font rendering using rustybuzz, so fonts render the same everywhere
- Many other such things
Why would I choose to do it that way? Because I have developed it primarily on desktop where I have much faster iteration speed. Aint nobody got time for iOS compilation and simulator. Once I finished the hard part on desktop, porting to iOS was much easier, and I didn’t lock myself in to Apple
Some of these would have been unimaginable without agents, like creating a UI library from scratch in Rust. But when you have infinite workforce, you can ask for crazy things like “create a textbox component from scratch”
What I’ve built is very similar in nature to CapCut, except that I am a single person and I’ve built it over 1 week
What have you built this Christmas with agents?
-
You could maybe work in the evening after work, but unless you are slacking at work full time, it won’t be the same thing as full immersion. ↩
-
-
Migrating @TextCortex to SimpleDoc. It's really easy with the CLI wizard! npx @simpledoc/simpledoc migrate We have a LOT of docs spanning back to 2022, pre coding agent era. Now we will have CI/CD in place so that coding agents can't litter the repo with random Markdown filesImage hidden