Entries for 2025

-
GPT 5.2 xhigh feels like a much more careful architecter and debugger, when it comes to complex systems But most people here think Opus 4.5 is the best model in that category There are 2 reasons AFAIS: - xhigh reasoning consumes significantly more tokens. You need to pay for ChatGPT Pro (200 usd) to be able to use it as a daily driver - It takes like 5x longer to finish a task, and most people lack the patience to wait for it. (But then it's more correct/doesn't need fixing) Opus 4.5 is good too, I think better in e.g. frontend design. But if you think it beats GPT 5.2 in every category, you are either too poor/stingy or have ADHD
-
Just 5 months ago, I was swearing at Claude 4 Sonnet like a Balkan uncle Models one-shotted the right thing only 20-30% of the time but did really stupid things the rest, and had to be handheld tightly Today they are much, much better. My psychology is a lot more at ease, and instead of swearing, I want to kiss them on the forehead most of the time Now I trust agents so much that I queue up 5-10 tasks before going to sleep. They work the whole night while I sleep and I wake up to resolved issues GPT 5.2 xhigh and Claude 4.5 Opus are already goated (GPT more so), can't wait for them to get even fasterImage hidden
-
Codex does not have support for subagents. I tried to use Claude Code to launch 8 Codex instances in parallel on separate tasks, but Opus 4.5 had difficulty following instructions So created a CLI tool to scan pending TODOs from a markdown file, and let me launch as many harnesses as I want (osolmaz/spawn on github) I currently use this for relatively read-only tasks like planning and finding root causes of bugs, because it's launching all the agents on the same repo and they might conflict Ideas: - Use @mitsuhiko's gh-issue-sync and run parallel agents directly on github issues - Create any new clones or worktrees for each task. I currently don't do this because I don't dare duplicate rust target dir 10x on my measly macbook air - Support modes other than tmux, e.g. launching a terminal like Ghostty - TUI for easy selection of issues/TODOs Other ideas are welcome!Image hiddenImage hidden
-
-
Friends of open source, we need your help! A lot of Manim Community accounts got compromised and deleted during Christmas Manim Community is a popular fork of @3blue1brown's original math animation engine Manim, and its accounts have over 5 YEARS of contributions, knowledge and following Apparently GitHub support already saw the request and in progress of restoring the GitHub org. But if anyone knows how to speed this up, if would be greatly appreciated! Unfortunately, the Discord and X accounts are deleted and less likely to return But there might still be a way to restore them, or at least the data? Re. Discord: Maybe @RhysSullivan's Answer Overflow has archived enough of the old server? That server contains YEARS of Q/A data and is vital for newcomers Re. X: Maybe someone high up can do something to restore the account? cc @nikitabier In the meanwhile, it would help a lot if you could follow the new account @manimcommunity and share this post! Thank you in advance!Image hidden
-
While a great feature, I never needed such a thing in Codex after GPT 5.2. It just one shots tasks without stopping So we have proof by existence that this problem can be solved without any such mechanism. Wish to see the same relentlessness in Anthropic models
-
2025 was the year of ̶a̶g̶e̶n̶t̶s̶ bugs Software felt much buggier compared to before, even from companies like Apple. Presumably because everyone started generating more code with AI Models are improving so hopefully 2026 will be the opposite. Even less bugs than pre-AI era
-
Have a long flight, so will think about this I have an internal 2023 TextCortex doc which models chatbots as state machines with internal and external states with immutability constraints on the external state (what is already sent to the user shall not be changed) Motivation was that a chatbot provider will always have state that they will want to keep hidden This was way before Responses and now deprecated Assistants API. It stood the test of time, because it was the most abstract thing I could think of @mitsuhiko is right about the risk of rushing to lock in an abstraction and locking in their weaknesses and faults Problem is, I could propose standards as much as I liked, but I don’t work at OpenAI or Anthropic, so nobody would care. Maybe a better place to start is open weights model libraries? To at least be able to demonstrate? What I know: it is against OpenAI’s or Anthropic’s self interests to create an interoperability layer that will accelerate their commoditization. Maybe Google, looking at their current market positioning? Or maybe we “wrappers” have a chance after all? There is a missing link between AI SDK, Langchain, and so on for other languages. We cannot keep duplicating same things in each ecosystem independently. We need to join forces and simplify all this!
-
This was simply because webapp fails to create a post and fails silently. The UX is still not good on this app. Make sure to write your posts somewhere else to not lose them
-
I gave Codex a task of porting an OpenCV tracking algorithm (CSRT) from C++ to Rust, so that I can directly use it in my project without having to cross-compile It one-shot the task perfectly in 1hr, and even developed a GUI on top of it. All I did was to provide the original source and algo paper I've spent years getting specialized in writing numerical code (computational mechanics, fem), and now AI can automate 95% of the low-level grunt work Acquiring these skills involved highly difficult, excruciating intellectual labor spanning many years, very similar to ML research. Doing tensor math, writing out the solver code, wondering why your solution is not converging, finally figuring out it was a sign typo after 2 days Kids these days both have it easy and hard. They can fast forward large chunks of the work, but then they will never understand things as deeply as someone who wrote the whole thing by hand I guess the more valuable skill now is being able to zoom in and out of abstraction levels quickly when needed. Using AI, but recognizing fast when it fails, learning what needs to be done, fixing it, zooming back out, repeat. Adaptive learning, a sort of "depth-on-demand". The quicker you can pick up new skills and knowledge, the more successful you will be
-
Depth on Demand
I gave Codex a task of porting an OpenCV tracking algorithm (CSRT) from C++ to Rust, so that I can directly use it in my project without having to cross-compile
It one-shot the task perfectly in 1hr, and even developed a GUI on top of it. All I did was to provide the original source and algo paper
I’ve spent years getting specialized in writing numerical code (computational mechanics, fem), and now AI can automate 95% of the low-level grunt work
Acquiring these skills involved highly difficult, excruciating intellectual labor spanning many years, very similar to ML research. Doing tensor math, writing out the solver code, wondering why your solution is not converging, finally figuring out it was a sign typo after 2 days
Kids these days both have it easy and hard. They can fast forward large chunks of the work, but then they will never understand things as deeply as someone who wrote the whole thing by hand
I guess the more valuable skill now is being able to zoom in and out of abstraction levels quickly when needed. Using AI, but recognizing fast when it fails, learning what needs to be done, fixing it, zooming back out, repeat. Adaptive learning, a sort of “depth-on-demand”. The quicker you can pick up new skills and knowledge, the more successful you will be
-
-
-
Now you can migrate your repo to SimpleDoc with a single command: npx -y @simpledoc/simpledoc migrate Step by step wizard will add timestamps to your files based on your git history, add missing YAML frontmatter, update your AGENTS md file https://t.co/yrciS8KtEwImage hidden
-
@bcherny Would be great if I could queue messages like in Codex https://t.co/mC25gNKWo3
-
-
_No text captured._Image hidden
-
Curious to hear what other hardcore agent users @simonw @mitsuhiko @steipete @badlogicgames think. I can't be the only one who does this. I feel like everybody ended up with the same workflow independent of each other, but somehow did not write about it (or I missed it)
-
-
How to stop AI agents from littering your codebase with Markdown files
A simple documentation workflow for AI agents.
For setup instructions, skip to the How to setup SimpleDoc in your repo section.
If you have used AI agents such as Anthropic’s Claude Code, OpenAI’s Codex, etc., you might have noticed their tendency to create markdown files at the repository root:
... ├── API_SPEC.md ├── ARCHITECTURE.md ├── BACKLOG.md ├── CLAUDE.md ├── CODE_REVIEW.md ├── DECISIONS.md ├── ENDPOINTS.md ├── IMPLEMENTATION_PLAN.md ├── NOTES.md ├── QA_CHECKLIST.md ├── SECURITY_PLAN.md └── src/ └── ... ├── TEST_COVERAGE.md ├── TEST_REPORTS.md ├── TEST_RESULTS.md ...The default behavior for models as of writing this in December 2025 is to create capitalized Markdown files at the repository root. This is of course very annoying, when you accidentally commit them and they accumulate over time.
The good news is, this problem is 100% solvable, by using a simple instruction in your AGENTS.md file:
**Attention agent!** Before creating ANY documentation, read the docs/HOW_TO_DOC.md file first. It contains guidelines on how to create documentation in this repository.But what should be in
docs/HOW_TO_DOC.mdfile and why is it a separate file? In my opinion, the instructions for solving this problem are too specific to be included in the AGENTS.md file. It’s generally a good idea to not inject them into every context.To solve this problem, I developed a lightweight standard over time, for organizing documentation in a codebase. It is framework-agnostic, unopinionated and designed to be human-readable/writable (as well as agents). I was surprised to be not able to find something similar enough online, crystallized the way I wanted it to be. So I created a specification myself, called SimpleDoc.
Basically, it tells the agent to
- Create documentation files in the
docs/folder, withYYYY-MM-DDprefixes and lowercase filenames, like2025-12-22-an-awesome-doc.md, so that they will by default be chronologically sorted. - Always include YAML frontmatter with author, so that you can identify who created it without checking git history, if you are working in a team.
- The exception here are timeless and general files like README.md, INSTALL.md, AGENTS.md, etc. which can be capitalized. But these are much rarer, so we can just follow the previous rules most of the time.
Here is your call to action to check the spec itself: SimpleDoc.
How to setup SimpleDoc in your repo
Run the following command from your repo root:
npx -y @simpledoc/simpledoc migrateThis starts an interactive wizard that will:
- Migrate existing Markdown docs to SimpleDoc conventions (move root docs into
docs/, rename toYYYY-MM-DD-…using git history, and optionally insert missing YAML frontmatter with per-file authors). - Ensure
AGENTS.mdcontains the reminder line and thatdocs/HOW_TO_DOC.mdexists (created from the bundled SimpleDoc template).
If you just want to preview what it would change:
npx -y @simpledoc/simpledoc migrate --dry-runIf you run into issues with the workflow or have suggestions for improvement, you can email me at onur@solmaz.io.
Happy documenting!
- Create documentation files in the
-
OpenAI won’t be able to monopolize this, the same reason Microsoft couldn’t monopolize the internet. The internet (of agents) is bigger than any one company
-
-
-
Codex feature request: Let me queue up /model changes Currently, if I try to run /model while responding, it tells me that I can't do that while the model is responding But I often want to gauge thinking budget in advance, like run a straightforward task with low reasoning and then start another one with high reasoning cc @thsottiaux
-
-
AI agents make any transductional task (like translation from language A to language B) trivial, especially when you can verify the output with compilers and tests The bottleneck is now curating the tests
-
I think X removed one of my posts yesterday about the new encrypted "Chat" rolling out to all users, and how you might lose all your past messages if you forget your passcode and do not have the app installed I can swear I clicked Post. Do they classify posts based on their topic and delete the ones they don't like? Anyway, we shall see, I am taking a screenshot and saving the URL.
-
-
Crazy that @cursor_ai disabled Gemini 3 Pro on my installation, toggled it right back on. I wonder why, too many complaints maybe? That it’s hard to control? On another note, disabling models without notification is dishonest product behavior. I would at least appreciate getting a notification, even when it might be against a company’s interests @sualehasif996
-
So is somebody already building “LLVM but for LLM APIs” in stealth or not? We have numerous libraries @langchain, Vercel AI SDK, LiteLLM, OpenRouter, the one we have built at @TextCortex, etc. But to my knowledge, none of these try to build a language agnostic IR for interoperability between providers (or at least market themselves as such) Like some standard and set of tools that will not lock you in langchain, ai sdk or anything like that, something lower level and less opinionated I feel like this is a job for the new Agentic AI Foundation cc @linuxfoundation, so maybe they are already working on it? I desperately want to start on such a project, but feel like I might get sniped 2 months after Anybody has any information on all this? cc @mitsuhiko @badlogicgames @steipete
-
-
This is how an agentic monorepo looks like. What was now a hurdle before is now a child's toy This side project started as a Python project earlier in 2025 Then I added an iOS app on top of it I rewrote the most important algorithms in Rust I rewrote the entire backend in Go and retired Python to be used purely for prototypes I wrote a webapp with Next.js With unit and integration tests for each component Lately written 99% by instructing agents Crazy mixed language programming going on in the background. Rust component used both by iOS app for offline and by go backend for online use case, FFI and all Number of lines in the repo: a couple 100k If you had told me I would be able do to all of this by myself 1 year ago, I would not have believed itImage hidden
-
This is huge. Natively supported stacked PRs on GitHub would make life much easier, especially with human AND AI reviews AI reviews with Codex/Claude/Gemini/Cursor Bugbot integrations are becoming especially important in small teams who are generating huge amounts of code AI reviews don't work well if you don't split your work to diffs smaller than a few hundred lines of code, so stacked PRs are already an integral part of developer experience in agentic workflows
-
-
CLI coding tools should give more control over message queueing Codex waits until end of turn to handle user message, Claude Code injects as soon as possible after tool response/assistant reply There is no reason why we cannot have both! New post (link below):Image hidden
-
-
-
Agentic coding tools should give more control over message queueing
Below: Why agentic coding tools like Cursor, Claude Code, OpenAI Codex, etc. should implement more ways of letting users queue messages.
See Peter Steinberger’s tweet where he queues
continue100 times to nudge the GPT-5-Codex model to not stop while working on a predictable, boring and long-running refactor task:This is necessary while working with a model like GPT-5-Codex. The reason is that the model has a tendency to stop generating at certain checkpoints, due to the way it has been trained, even when you instruct it to
FINISH IT UNTIL COMPLETION!!1!. So the only way to get it to finish something is to use the message queue.1But this isn’t the only use case for queued messages. For example, you can use the model to retrieve files into its context, before starting off a related task. Say you want to find the root cause of a
<bug in component X>. Then you can queueExplain how <component X> works in plain language. Do not omit any details.Find the root cause of <bug> in <component X>.
This will generally help the model to find the root cause easier, or make more accurate predictions about the root cause, by having the context about the component.
Another example: After exploring a design in a dialogue, you can queue the next steps to implement it.
<Prior conversation exploring how to design a new feature>Create an implementation plan for that in the docs/ folder. Include all the details we discussedCommit and push the docImplement the feature according to the plan.Continue implementing the feature until it is done. Ignore this if the task is already completed.Continue implementing the feature until it is done. Ignore this if the task is already completed.
… you get the idea.
I generally queue like this when the feature is specified enough in the conversation already. If it’s underspecified, then the model will make up stuff.
When I first moved from Claude Code to Codex, the way it implemented queued messages was annoying (more on the difference below). But as I grew accustomed to it, it started to feel a lot like something I saw elsewhere before: chess premoves.
Chess???
A premove is a relatively recent invention in chess which is made possible by digital chess engines. When the feature is turned on, you don’t need to wait for your opponent to finish their move, and instead can queue your next move. It then gets executed automatically if the queued move is valid after your opponent’s move:
If you are fast enough, this let’s you move without using up your time in bullet chess, and even lets you queue up entire mate-in-N sequences, resulting in highly entertaining cases like the video above.
I tend to think of message queueing as the same thing: when applied effectively, it saves you a lot of time, when you can already predict the next move.
In other words, you should queue (or premove) when your next choice is decision-insensitive to the information you will receive in the next turn—so waiting wouldn’t change what you do, it would only delay doing it.
With this perspective, some obvious candidates for queuing in agentic codeing are rote tasks that come before and after “serious work”, e.g:
- making the agent explain the codebase,
- creating implementation plans,
- fixing linting errors,
- updating documentation during work before starting off a subsequent step,
- committing and pushing,
- and so on.
Different ways CLI agents implement queued messages
As I have mentioned above, Claude Code implements queued messages differently from OpenAI Codex. In fact, there are three main approaches that I can think of in this design space, which is based on when a user’s new input takes effect:
-
Post-turn queuing (FIFO2): User messages wait until the current action finishes completely before they’re handled. Example: OpenAI Codex CLI.
-
Boundary-aware queuing (Soft Interrupt): New messages are inserted at natural breakpoints, like after finishing a tool call, assistant reply or a task in the TODO list. This changes the model’s course of action smoothly, without stopping ongoing generation. Example: Claude Code, Cursor.
-
Immediate queuing (Hard Interrupt): New user messages immediately stop the current action/generation, discarding ongoing work and restarting the assistant’s generation from scratch. I have not seen any tool that implements this yet, but it could be an option for the impatient.
Why not implement all of them?
And here is my title-sake argument: When I move away from Claude Code, I miss boundary-aware queuing. When I move away from OpenAI Codex, I miss FIFO queueing.
I don’t see a reason why we could not implement all of them in all agentic tools. It could be controlled by a key combo like
Ctrl+Enter, a submenu, or a button, depending on whether you are in the terminal or not.Having the option would definitely make a difference in agentic workflows where you are running 3-4 agents in parallel.
So if you are reading this and are implementing an agentic coding tool, I would be happy if you took all this into consideration!
-
Pro tip: Don’t just queue
continueby itself, because the model might get loose from its leash and start to make up and execute random tasks, especially after context compaction. Always specify what you want it to continue on, e.g.Continue handling the linting errors until none remain. Ignore this if the task is already completed.↩ -
First-in, first-out. ↩
-
At least some people at OpenAI must be thinking about buying @astral_sh
-
who remembers search engine aggregators from early 2000s?
-
-
-
-
-
-
-
Google is making progress… I did not have to request access on Vertex AI for Gemini 3 Pro this time to deploy it to @TextCortex
-
-
"The more a task/job is verifiable, the more amenable it is to automation in the new programming paradigm. If it is not verifiable, it has to fall out from neural net magic of generalization fingers crossed, or via weaker means like imitation."
-
-
This post makes no sense Please consider again and look at @cloudfleet_k8s. You might regret your decision
-
Working on observability is underrated
-
@rakyll @GergelyOrosz Should scrape some austrian websites :)
-
-
Vibecoding this blog
I finally brought myself to develop certain features for this blog which I wanted to do for some time, having a button to toggle light/dark mode, being able to permalink page sections, having a button to copy page content, etc.
I always have a tendency to procrastinate with cosmetics, so I developed a habit to mentally force myself not to care about looks and instead focus on the actual content. Doing the changes I have pulled off in the last 2 hours would have been impossible in pre-LLM era. So I kept the awful default Jekyll Minima theme, and did not spend more thought on it. I had actually went through many different themes in this blog before, and I had switched to Minima precisely because of that: I was spending too much time.
I really like designing things visually. I had interest in typography while studying, and I even went as far to design a font, write all my notes in LaTeX, etc. Then I found out that such skills are not valued in the world, and had no luxury to dwell on such things anymore once I started working.
But now it’s different. When I can do what I want 10 times faster with 10 times less attention, I can just do the design I want. Before I thought it was a flex to use default themes, because it showed a) that the person does not care and b) that they had more important things to do.
Well, now my opinion has changed. In the era where making something look good takes a few hours, using a default theme means something else to me: lack of taste.
For this blog, I just vendored Minima and let gpt-5-codex rip on it. Vendoring pattern is getting more popular with libraries like shadcn, and I expect it to be ever more popular with open source libraries, with AI tools becoming more prevalent.
I don’t expect simple frontend development to be in a good place ever again. I don’t expect anyone to outsource simple static site development to humans anymore, when you can get the exact thing you want at virtually no cost.
-
@thsottiaux Let me use my Pro/Plus plans in Codex GH Action https://t.co/0Fw1rLmCED
-
TIL @OpenAI now has a GitHub action for Codex, similar to Claude Code This lets you invoke Codex in a more controlled way in your repos You must still pay API prices though. Let's see if OpenAI will introduce a way to connect your Pro plan, like in @AnthropicAI paid plansImage hidden
-
Google's Code Review Guidelines (GitHub Adaptation)
This is an adaptation of the original Google’s Code Review Guidelines, to use GitHub specific terminology. Google has their own internal tools for version control (Piper) and code review (Critique). They have their own terminology, like “Change List” (CL) instead of “Pull Request” (PR) which most developers are more familiar with. The changes are minimal and the content is kept as close to the original as possible. The hope is to make this gem accessible to a wider audience.
I also combined the whole set of documents into a single file, to make it easier to consume. You can find my fork here. If you notice any mistakes, please feel free to submit a PR to the fork.
Introduction
A code review is a process where someone other than the author(s) of a piece of code examines that code.
At Google, we use code review to maintain the quality of our code and products.
This documentation is the canonical description of Google’s code review processes and policies.
This page is an overview of our code review process. There are two other large documents that are a part of this guide:
- How To Do A Code Review: A detailed guide for code reviewers.
- The PR Author’s Guide: A detailed guide for developers whose PRs are going through review.
What Do Code Reviewers Look For?
Code reviews should look at:
- Design: Is the code well-designed and appropriate for your system?
- Functionality: Does the code behave as the author likely intended? Is the way the code behaves good for its users?
- Complexity: Could the code be made simpler? Would another developer be able to easily understand and use this code when they come across it in the future?
- Tests: Does the code have correct and well-designed automated tests?
- Naming: Did the developer choose clear names for variables, classes, methods, etc.?
- Comments: Are the comments clear and useful?
- Style: Does the code follow our style guides?
- Documentation: Did the developer also update relevant documentation?
See How To Do A Code Review for more information.
Picking the Best Reviewers
In general, you want to find the best reviewers you can who are capable of responding to your review within a reasonable period of time.
The best reviewer is the person who will be able to give you the most thorough and correct review for the piece of code you are writing. This usually means the owner(s) of the code, who may or may not be the people in the CODEOWNERS file. Sometimes this means asking different people to review different parts of the PR.
If you find an ideal reviewer but they are not available, you should at least CC them on your change.
In-Person Reviews (and Pair Programming)
If you pair-programmed a piece of code with somebody who was qualified to do a good code review on it, then that code is considered reviewed.
You can also do in-person code reviews where the reviewer asks questions and the developer of the change speaks only when spoken to.
See Also
- How To Do A Code Review: A detailed guide for code reviewers.
- The PR Author’s Guide: A detailed guide for developers whose PRs are going through review.
How to do a code review
The pages in this section contain recommendations on the best way to do code reviews, based on long experience. All together they represent one complete document, broken up into many separate sections. You don’t have to read them all, but many people have found it very helpful to themselves and their team to read the entire set.
- The Standard of Code Review
- What to Look For In a Code Review
- Navigating a PR in Review
- Speed of Code Reviews
- How to Write Code Review Comments
- Handling Pushback in Code Reviews
See also the PR Author’s Guide, which gives detailed guidance to developers whose PRs are undergoing review.
The Standard of Code Review
The primary purpose of code review is to make sure that the overall code health of Google’s code base is improving over time. All of the tools and processes of code review are designed to this end.
In order to accomplish this, a series of trade-offs have to be balanced.
First, developers must be able to make progress on their tasks. If you never merge an improvement into the codebase, then the codebase never improves. Also, if a reviewer makes it very difficult for any change to go in, then developers are disincentivized to make improvements in the future.
On the other hand, it is the duty of the reviewer to make sure that each PR is of such a quality that the overall code health of their codebase is not decreasing as time goes on. This can be tricky, because often, codebases degrade through small decreases in code health over time, especially when a team is under significant time constraints and they feel that they have to take shortcuts in order to accomplish their goals.
Also, a reviewer has ownership and responsibility over the code they are reviewing. They want to ensure that the codebase stays consistent, maintainable, and all of the other things mentioned in “What to look for in a code review.”
Thus, we get the following rule as the standard we expect in code reviews:
In general, reviewers should favor approving a PR once it is in a state where it definitely improves the overall code health of the system being worked on, even if the PR isn’t perfect.
That is the senior principle among all of the code review guidelines.
There are limitations to this, of course. For example, if a PR adds a feature that the reviewer doesn’t want in their system, then the reviewer can certainly deny approval even if the code is well-designed.
A key point here is that there is no such thing as “perfect” code—there is only better code. Reviewers should not require the author to polish every tiny piece of a PR before granting approval. Rather, the reviewer should balance out the need to make forward progress compared to the importance of the changes they are suggesting. Instead of seeking perfection, what a reviewer should seek is continuous improvement. A PR that, as a whole, improves the maintainability, readability, and understandability of the system shouldn’t be delayed for days or weeks because it isn’t “perfect.”
Reviewers should always feel free to leave comments expressing that something could be better, but if it’s not very important, prefix it with something like “Nit: “ to let the author know that it’s just a point of polish that they could choose to ignore.
Note: Nothing in this document justifies merging PRs that definitely worsen the overall code health of the system. The only time you would do that would be in an emergency.
Mentoring
Code review can have an important function of teaching developers something new about a language, a framework, or general software design principles. It’s always fine to leave comments that help a developer learn something new. Sharing knowledge is part of improving the code health of a system over time. Just keep in mind that if your comment is purely educational, but not critical to meeting the standards described in this document, prefix it with “Nit: “ or otherwise indicate that it’s not mandatory for the author to resolve it in this PR.
Principles
-
Technical facts and data overrule opinions and personal preferences.
-
On matters of style, the style guide is the absolute authority. Any purely style point (whitespace, etc.) that is not in the style guide is a matter of personal preference. The style should be consistent with what is there. If there is no previous style, accept the author’s.
-
Aspects of software design are almost never a pure style issue or just a personal preference. They are based on underlying principles and should be weighed on those principles, not simply by personal opinion. Sometimes there are a few valid options. If the author can demonstrate (either through data or based on solid engineering principles) that several approaches are equally valid, then the reviewer should accept the preference of the author. Otherwise the choice is dictated by standard principles of software design.
-
If no other rule applies, then the reviewer may ask the author to be consistent with what is in the current codebase, as long as that doesn’t worsen the overall code health of the system.
Resolving Conflicts
In any conflict on a code review, the first step should always be for the developer and reviewer to try to come to consensus, based on the contents of this document and the other documents in The PR Author’s Guide and this Reviewer Guide.
When coming to consensus becomes especially difficult, it can help to have a face-to-face meeting or a video conference between the reviewer and the author, instead of just trying to resolve the conflict through code review comments. (If you do this, though, make sure to record the results of the discussion as a comment on the PR, for future readers.)
If that doesn’t resolve the situation, the most common way to resolve it would be to escalate. Often the escalation path is to a broader team discussion, having a Technical Lead weigh in, asking for a decision from a maintainer of the code, or asking an Eng Manager to help out. Don’t let a PR sit around because the author and the reviewer can’t come to an agreement.
Next: What to look for in a code review
What to look for in a code review
Note: Always make sure to take into account The Standard of Code Review when considering each of these points.
Design
The most important thing to cover in a review is the overall design of the PR. Do the interactions of various pieces of code in the PR make sense? Does this change belong in your codebase, or in a library? Does it integrate well with the rest of your system? Is now a good time to add this functionality?
Functionality
Does this PR do what the developer intended? Is what the developer intended good for the users of this code? The “users” are usually both end-users (when they are affected by the change) and developers (who will have to “use” this code in the future).
Mostly, we expect developers to test PRs well-enough that they work correctly by the time they get to code review. However, as the reviewer you should still be thinking about edge cases, looking for concurrency problems, trying to think like a user, and making sure that there are no bugs that you see just by reading the code.
You can validate the PR if you want—the time when it’s most important for a reviewer to check a PR’s behavior is when it has a user-facing impact, such as a UI change. It’s hard to understand how some changes will impact a user when you’re just reading the code. For changes like that, you can have the developer give you a demo of the functionality if it’s too inconvenient to patch in the PR and try it yourself.
Another time when it’s particularly important to think about functionality during a code review is if there is some sort of parallel programming going on in the PR that could theoretically cause deadlocks or race conditions. These sorts of issues are very hard to detect by just running the code and usually need somebody (both the developer and the reviewer) to think through them carefully to be sure that problems aren’t being introduced. (Note that this is also a good reason not to use concurrency models where race conditions or deadlocks are possible—it can make it very complex to do code reviews or understand the code.)
Complexity
Is the PR more complex than it should be? Check this at every level of the PR—are individual lines too complex? Are functions too complex? Are classes too complex? “Too complex” usually means “can’t be understood quickly by code readers.” It can also mean “developers are likely to introduce bugs when they try to call or modify this code.”
A particular type of complexity is over-engineering, where developers have made the code more generic than it needs to be, or added functionality that isn’t presently needed by the system. Reviewers should be especially vigilant about over-engineering. Encourage developers to solve the problem they know needs to be solved now, not the problem that the developer speculates might need to be solved in the future. The future problem should be solved once it arrives and you can see its actual shape and requirements in the physical universe.
Tests
Ask for unit, integration, or end-to-end tests as appropriate for the change. In general, tests should be added in the same PR as the production code unless the PR is handling an emergency.
Make sure that the tests in the PR are correct, sensible, and useful. Tests do not test themselves, and we rarely write tests for our tests—a human must ensure that tests are valid.
Will the tests actually fail when the code is broken? If the code changes beneath them, will they start producing false positives? Does each test make simple and useful assertions? Are the tests separated appropriately between different test methods?
Remember that tests are also code that has to be maintained. Don’t accept complexity in tests just because they aren’t part of the main binary.
Naming
Did the developer pick good names for everything? A good name is long enough to fully communicate what the item is or does, without being so long that it becomes hard to read.
Comments
Did the developer write clear comments in understandable English? Are all of the comments actually necessary? Usually comments are useful when they explain why some code exists, and should not be explaining what some code is doing. If the code isn’t clear enough to explain itself, then the code should be made simpler. There are some exceptions (regular expressions and complex algorithms often benefit greatly from comments that explain what they’re doing, for example) but mostly comments are for information that the code itself can’t possibly contain, like the reasoning behind a decision.
It can also be helpful to look at comments that were there before this PR. Maybe there is a TODO that can be removed now, a comment advising against this change being made, etc.
Note that comments are different from documentation of classes, modules, or functions, which should instead express the purpose of a piece of code, how it should be used, and how it behaves when used.
Style
We have style guides at Google for all of our major languages, and even for most of the minor languages. Make sure the PR follows the appropriate style guides.
If you want to improve some style point that isn’t in the style guide, prefix your comment with “Nit:” to let the developer know that it’s a nitpick that you think would improve the code but isn’t mandatory. Don’t block PRs from being merged based only on personal style preferences.
The author of the PR should not include major style changes combined with other changes. It makes it hard to see what is being changed in the PR, makes merges and rollbacks more complex, and causes other problems. For example, if the author wants to reformat the whole file, have them send you just the reformatting as one PR, and then send another PR with their functional changes after that.
Consistency
What if the existing code is inconsistent with the style guide? Per our code review principles, the style guide is the absolute authority: if something is required by the style guide, the PR should follow the guidelines.
In some cases, the style guide makes recommendations rather than declaring requirements. In these cases, it’s a judgment call whether the new code should be consistent with the recommendations or the surrounding code. Bias towards following the style guide unless the local inconsistency would be too confusing.
If no other rule applies, the author should maintain consistency with the existing code.
Either way, encourage the author to file a bug and add a TODO for cleaning up existing code.
Documentation
If a PR changes how users build, test, interact with, or release code, check to see that it also updates associated documentation, including READMEs, repository docs, and any generated reference docs. If the PR deletes or deprecates code, consider whether the documentation should also be deleted. If documentation is missing, ask for it.
Every Line
In the general case, look at every line of code that you have been assigned to review. Some things like data files, generated code, or large data structures you can scan over sometimes, but don’t scan over a human-written class, function, or block of code and assume that what’s inside of it is okay. Obviously some code deserves more careful scrutiny than other code—that’s a judgment call that you have to make—but you should at least be sure that you understand what all the code is doing.
If it’s too hard for you to read the code and this is slowing down the review, then you should let the developer know that and wait for them to clarify it before you try to review it. At Google, we hire great software engineers, and you are one of them. If you can’t understand the code, it’s very likely that other developers won’t either. So you’re also helping future developers understand this code, when you ask the developer to clarify it.
If you understand the code but you don’t feel qualified to do some part of the review, make sure there is a reviewer on the PR who is qualified, particularly for complex issues such as privacy, security, concurrency, accessibility, internationalization, etc.
Exceptions
What if it doesn’t make sense for you to review every line? For example, you are one of multiple reviewers on a PR and may be asked:
- To review only certain files that are part of a larger change.
- To review only certain aspects of the PR, such as the high-level design, privacy or security implications, etc.
In these cases, note in a comment which parts you reviewed. Prefer giving Approve with comments .
If you instead wish to grant Approval after confirming that other reviewers have reviewed other parts of the PR, note this explicitly in a comment to set expectations. Aim to respond quickly once the PR has reached the desired state.
Context
It is often helpful to look at the PR in a broad context. Usually the code review tool will only show you a few lines of code around the parts that are being changed. Sometimes you have to look at the whole file to be sure that the change actually makes sense. For example, you might see only four new lines being added, but when you look at the whole file, you see those four lines are in a 50-line method that now really needs to be broken up into smaller methods.
It’s also useful to think about the PR in the context of the system as a whole. Is this PR improving the code health of the system or is it making the whole system more complex, less tested, etc.? Don’t accept PRs that degrade the code health of the system. Most systems become complex through many small changes that add up, so it’s important to prevent even small complexities in new changes.
Good Things
If you see something nice in the PR, tell the developer, especially when they addressed one of your comments in a great way. Code reviews often just focus on mistakes, but they should offer encouragement and appreciation for good practices, as well. It’s sometimes even more valuable, in terms of mentoring, to tell a developer what they did right than to tell them what they did wrong.
Summary
In doing a code review, you should make sure that:
- The code is well-designed.
- The functionality is good for the users of the code.
- Any UI changes are sensible and look good.
- Any parallel programming is done safely.
- The code isn’t more complex than it needs to be.
- The developer isn’t implementing things they might need in the future but don’t know they need now.
- Code has appropriate unit tests.
- Tests are well-designed.
- The developer used clear names for everything.
- Comments are clear and useful, and mostly explain why instead of what.
- Code is appropriately documented (generally in repository docs).
- The code conforms to our style guides.
Make sure to review every line of code you’ve been asked to review, look at the context, make sure you’re improving code health, and compliment developers on good things that they do.
Next: Navigating a PR in Review
Navigating a PR in review
Summary
Now that you know what to look for, what’s the most efficient way to manage a review that’s spread across multiple files?
- Does the change make sense? Does it have a good description?
- Look at the most important part of the change first. Is it well-designed overall?
- Look at the rest of the PR in an appropriate sequence.
Step One: Take a broad view of the change
Look at the PR description and what the PR does in general. Does this change even make sense? If this change shouldn’t have happened in the first place, please respond immediately with an explanation of why the change should not be happening. When you reject a change like this, it’s also a good idea to suggest to the developer what they should have done instead.
For example, you might say “Looks like you put some good work into this, thanks! However, we’re actually going in the direction of removing the FooWidget system that you’re modifying here, and so we don’t want to make any new modifications to it right now. How about instead you refactor our new BarWidget class?”
Note that not only did the reviewer reject the current PR and provide an alternative suggestion, but they did it courteously. This kind of courtesy is important because we want to show that we respect each other as developers even when we disagree.
If you get more than a few PRs that represent changes you don’t want to make, you should consider re-working your team’s development process or the posted process for external contributors so that there is more communication before PRs are written. It’s better to tell people “no” before they’ve done a ton of work that now has to be thrown away or drastically re-written.
Step Two: Examine the main parts of the PR
Find the file or files that are the “main” part of this PR. Often, there is one file that has the largest number of logical changes, and it’s the major piece of the PR. Look at these major parts first. This helps give context to all of the smaller parts of the PR, and generally accelerates doing the code review. If the PR is too large for you to figure out which parts are the major parts, ask the developer what you should look at first, or ask them to split up the PR into multiple PRs.
If you see some major design problems with this part of the PR, you should send those comments immediately, even if you don’t have time to review the rest of the PR right now. In fact, reviewing the rest of the PR might be a waste of time, because if the design problems are significant enough, a lot of the other code under review is going to disappear and not matter anyway.
There are two major reasons it’s so important to send these major design comments out immediately:
- Developers often mail a PR and then immediately start new work based on that PR while they wait for review. If there are major design problems in the PR you’re reviewing, they’re also going to have to re-work their later PR. You want to catch them before they’ve done too much extra work on top of the problematic design.
- Major design changes take longer to do than small changes. Developers nearly all have deadlines; in order to make those deadlines and still have quality code in the codebase, the developer needs to start on any major re-work of the PR as soon as possible.
Step Three: Look through the rest of the PR in an appropriate sequence
Once you’ve confirmed there are no major design problems with the PR as a whole, try to figure out a logical sequence to look through the files while also making sure you don’t miss reviewing any file. Usually after you’ve looked through the major files, it’s simplest to just go through each file in the order that the code review tool presents them to you. Sometimes it’s also helpful to read the tests first before you read the main code, because then you have an idea of what the change is supposed to be doing.
Next: Speed of Code Reviews
Speed of Code Reviews
Why Should Code Reviews Be Fast?
At Google, we optimize for the speed at which a team of developers can produce a product together, as opposed to optimizing for the speed at which an individual developer can write code. The speed of individual development is important, it’s just not as important as the velocity of the entire team.
When code reviews are slow, several things happen:
- The velocity of the team as a whole is decreased. Yes, the individual who doesn’t respond quickly to the review gets other work done. However, new features and bug fixes for the rest of the team are delayed by days, weeks, or months as each PR waits for review and re-review.
- Developers start to protest the code review process. If a reviewer only responds every few days, but requests major changes to the PR each time, that can be frustrating and difficult for developers. Often, this is expressed as complaints about how “strict” the reviewer is being. If the reviewer requests the same substantial changes (changes which really do improve code health), but responds quickly every time the developer makes an update, the complaints tend to disappear. Most complaints about the code review process are actually resolved by making the process faster.
- Code health can be impacted. When reviews are slow, there is increased pressure to allow developers to merge PRs that are not as good as they could be. Slow reviews also discourage code cleanups, refactorings, and further improvements to existing PRs.
How Fast Should Code Reviews Be?
If you are not in the middle of a focused task, you should do a code review shortly after it comes in.
One business day is the maximum time it should take to respond to a code review request (i.e., first thing the next morning).
Following these guidelines means that a typical PR should get multiple rounds of review (if needed) within a single day.
Speed vs. Interruption
There is one time where the consideration of personal velocity trumps team velocity. If you are in the middle of a focused task, such as writing code, don’t interrupt yourself to do a code review. Research has shown that it can take a long time for a developer to get back into a smooth flow of development after being interrupted. So interrupting yourself while coding is actually more expensive to the team than making another developer wait a bit for a code review.
Instead, wait for a break point in your work before you respond to a request for review. This could be when your current coding task is completed, after lunch, returning from a meeting, coming back from the breakroom, etc.
Fast Responses
When we talk about the speed of code reviews, it is the response time that we are concerned with, as opposed to how long it takes a PR to get through the whole review and be merged. The whole process should also be fast, ideally, but it’s even more important for the individual responses to come quickly than it is for the whole process to happen rapidly.
Even if it sometimes takes a long time to get through the entire review process, having quick responses from the reviewer throughout the process significantly eases the frustration developers can feel with “slow” code reviews.
If you are too busy to do a full review on a PR when it comes in, you can still send a quick response that lets the developer know when you will get to it, suggest other reviewers who might be able to respond more quickly, or provide some initial broad comments. (Note: none of this means you should interrupt coding even to send a response like this—send the response at a reasonable break point in your work.)
It is important that reviewers spend enough time on review that they are certain their “Approve” means “this code meets our standards.” However, individual responses should still ideally be fast.
Cross-Time-Zone Reviews
When dealing with time zone differences, try to get back to the author while they have time to respond before the end of their working hours. If they have already finished work for the day, then try to make sure your review is done before they start work the next day.
Approve With Comments (LGTM)
In order to speed up code reviews, there are certain situations in which a reviewer should Approve even though they are also leaving unresolved comments on the PR. This should be done when at least one of the following applies:
- The reviewer is confident that the developer will appropriately address all the reviewer’s remaining comments.
- The comments don’t have to be addressed by the developer.
- The suggestions are minor, e.g. sort imports, fix a nearby typo, apply a suggested fix, remove an unused dep, etc.
The reviewer should specify which of these options they intend, if it is not otherwise clear.
Approve With Comments is especially worth considering when the developer and reviewer are in different time zones and otherwise the developer would be waiting for a whole day just to get approval.
Large PRs
If somebody sends you a code review that is so large you’re not sure when you will be able to have time to review it, your typical response should be to ask the developer to split the PR into several smaller PRs that build on each other, instead of one huge PR that has to be reviewed all at once. This is usually possible and very helpful to reviewers, even if it takes additional work from the developer.
If a PR can’t be broken up into smaller PRs, and you don’t have time to review the entire thing quickly, then at least write some comments on the overall design of the PR and send it back to the developer for improvement. One of your goals as a reviewer should be to always unblock the developer or enable them to take some sort of further action quickly, without sacrificing code health to do so.
Code Review Improvements Over Time
If you follow these guidelines and you are strict with your code reviews, you should find that the entire code review process tends to go faster and faster over time. Developers learn what is required for healthy code, and send you PRs that are great from the start, requiring less and less review time. Reviewers learn to respond quickly and not add unnecessary latency into the review process. But don’t compromise on the code review standards or quality for an imagined improvement in velocity—it’s not actually going to make anything happen more quickly, in the long run.
Emergencies
There are also emergencies where PRs must pass through the whole review process very quickly, and where the quality guidelines would be relaxed. However, please see What Is An Emergency? for a description of which situations actually qualify as emergencies and which don’t.
Next: How to Write Code Review Comments
How to write code review comments
Summary
- Be kind.
- Explain your reasoning.
- Balance giving explicit directions with just pointing out problems and letting the developer decide.
- Encourage developers to simplify code or add code comments instead of just explaining the complexity to you.
Courtesy
In general, it is important to be courteous and respectful while also being very clear and helpful to the developer whose code you are reviewing. One way to do this is to be sure that you are always making comments about the code and never making comments about the developer. You don’t always have to follow this practice, but you should definitely use it when saying something that might otherwise be upsetting or contentious. For example:
Bad: “Why did you use threads here when there’s obviously no benefit to be gained from concurrency?”
Good: “The concurrency model here is adding complexity to the system without any actual performance benefit that I can see. Because there’s no performance benefit, it’s best for this code to be single-threaded instead of using multiple threads.”
Explain Why
One thing you’ll notice about the “good” example from above is that it helps the developer understand why you are making your comment. You don’t always need to include this information in your review comments, but sometimes it’s appropriate to give a bit more explanation around your intent, the best practice you’re following, or how your suggestion improves code health.
Giving Guidance
In general it is the developer’s responsibility to fix a PR, not the reviewer’s. You are not required to do detailed design of a solution or write code for the developer.
This doesn’t mean the reviewer should be unhelpful, though. In general you should strike an appropriate balance between pointing out problems and providing direct guidance. Pointing out problems and letting the developer make a decision often helps the developer learn, and makes it easier to do code reviews. It also can result in a better solution, because the developer is closer to the code than the reviewer is.
However, sometimes direct instructions, suggestions, or even code are more helpful. The primary goal of code review is to get the best PR possible. A secondary goal is improving the skills of developers so that they require less and less review over time.
Remember that people learn from reinforcement of what they are doing well and not just what they could do better. If you see things you like in the PR, comment on those too! Examples: developer cleaned up a messy algorithm, added exemplary test coverage, or you as the reviewer learned something from the PR. Just as with all comments, include why you liked something, further encouraging the developer to continue good practices.
Label comment severity
Consider labeling the severity of your comments, differentiating required changes from guidelines or suggestions.
Here are some examples:
Nit: This is a minor thing. Technically you should do it, but it won’t hugely impact things.
Optional (or Consider): I think this may be a good idea, but it’s not strictly required.
FYI: I don’t expect you to do this in this PR, but you may find this interesting to think about for the future.
This makes review intent explicit and helps authors prioritize the importance of various comments. It also helps avoid misunderstandings; for example, without comment labels, authors may interpret all comments as mandatory, even if some comments are merely intended to be informational or optional.
Accepting Explanations
If you ask a developer to explain a piece of code that you don’t understand, that should usually result in them rewriting the code more clearly. Occasionally, adding a comment in the code is also an appropriate response, as long as it’s not just explaining overly complex code.
Explanations written only in the code review tool are not helpful to future code readers. They are acceptable only in a few circumstances, such as when you are reviewing an area you are not very familiar with and the developer explains something that normal readers of the code would have already known.
Next: Handling Pushback in Code Reviews
Handling pushback in code reviews
Sometimes a developer will push back on a code review. Either they will disagree with your suggestion or they will complain that you are being too strict in general.
Who is right?
When a developer disagrees with your suggestion, first take a moment to consider if they are correct. Often, they are closer to the code than you are, and so they might really have a better insight about certain aspects of it. Does their argument make sense? Does it make sense from a code health perspective? If so, let them know that they are right and let the issue drop.
However, developers are not always right. In this case the reviewer should further explain why they believe that their suggestion is correct. A good explanation demonstrates both an understanding of the developer’s reply, and additional information about why the change is being requested.
In particular, when the reviewer believes their suggestion will improve code health, they should continue to advocate for the change, if they believe the resulting code quality improvement justifies the additional work requested. Improving code health tends to happen in small steps.
Sometimes it takes a few rounds of explaining a suggestion before it really sinks in. Just make sure to always stay polite and let the developer know that you hear what they’re saying, you just don’t agree.
Upsetting Developers
Reviewers sometimes believe that the developer will be upset if the reviewer insists on an improvement. Sometimes developers do become upset, but it is usually brief and they become very thankful later that you helped them improve the quality of their code. Usually, if you are polite in your comments, developers actually don’t become upset at all, and the worry is just in the reviewer’s mind. Upsets are usually more about the way comments are written than about the reviewer’s insistence on code quality.
Cleaning It Up Later
A common source of push back is that developers (understandably) want to get things done. They don’t want to go through another round of review just to get this PR in. So they say they will clean something up in a later PR, and thus you should Approve this PR now. Some developers are very good about this, and will immediately write a follow-up PR that fixes the issue. However, experience shows that as more time passes after a developer writes the original PR, the less likely this clean up is to happen. In fact, usually unless the developer does the clean up immediately after the present PR, it never happens. This isn’t because developers are irresponsible, but because they have a lot of work to do and the cleanup gets lost or forgotten in the press of other work. Thus, it is usually best to insist that the developer clean up their PR now, before the code is in the codebase and “done.” Letting people “clean things up later” is a common way for codebases to degenerate.
If a PR introduces new complexity, it must be cleaned up before merge unless it is an emergency. If the PR exposes surrounding problems and they can’t be addressed right now, the developer should file a bug for the cleanup and assign it to themselves so that it doesn’t get lost. They can optionally also write a TODO comment in the code that references the filed bug.
General Complaints About Strictness
If you previously had fairly lax code reviews and you switch to having strict reviews, some developers will complain very loudly. Improving the speed of your code reviews usually causes these complaints to fade away.
Sometimes it can take months for these complaints to fade away, but eventually developers tend to see the value of strict code reviews as they see what great code they help generate. Sometimes the loudest protesters even become your strongest supporters once something happens that causes them to really see the value you’re adding by being strict.
Resolving Conflicts
If you are following all of the above but you still encounter a conflict between yourself and a developer that can’t be resolved, see The Standard of Code Review for guidelines and principles that can help resolve the conflict.
The PR author’s guide to getting through code review
The pages in this section contain best practices for developers going through code review. These guidelines should help you get through reviews faster and with higher-quality results. You don’t have to read them all, but they are intended to apply to every Google developer, and many people have found it helpful to read the whole set.
See also How to Do a Code Review, which gives detailed guidance for code reviewers.
Writing good PR descriptions
A PR description is a public record of change, and it is important that it communicates:
-
What change is being made? This should summarize the major changes such that readers have a sense of what is being changed without needing to read the entire PR.
-
Why are these changes being made? What contexts did you have as an author when making this change? Were there decisions you made that aren’t reflected in the source code? etc.
The PR description will become a permanent part of our version control history and will possibly be read by hundreds of people over the years.
Future developers will search for your PR based on its description. Someone in the future might be looking for your change because of a faint memory of its relevance but without the specifics handy. If all the important information is in the code and not the description, it’s going to be a lot harder for them to locate your PR.
And then, after they find the PR, will they be able to understand why the change was made? Reading source code may reveal what the software is doing but it may not reveal why it exists, which can make it harder for future developers to know whether they can move Chesterton’s fence.
A well-written PR description will help those future engineers – sometimes, including yourself!
First Line
- Short summary of what is being done.
- Complete sentence, written as though it was an order.
- Follow by empty line.
The first line of a PR description should be a short summary of specifically what is being done by the PR, followed by a blank line. This is what appears in version control history summaries, so it should be informative enough that future code searchers don’t have to read your PR or its whole description to understand what your PR actually did or how it differs from other PRs. That is, the first line should stand alone, allowing readers to skim through code history much faster.
Try to keep your first line short, focused, and to the point. The clarity and utility to the reader should be the top concern.
By tradition, the first line of a PR description is a complete sentence, written as though it were an order (an imperative sentence). For example, say "Delete the FizzBuzz RPC and replace it with the new system.” instead of "Deleting the FizzBuzz RPC and replacing it with the new system.” You don’t have to write the rest of the description as an imperative sentence, though.
Body is Informative
The first line should be a short, focused summary, while the rest of the description should fill in the details and include any supplemental information a reader needs to understand the change holistically. It might include a brief description of the problem that’s being solved, and why this is the best approach. If there are any shortcomings to the approach, they should be mentioned. If relevant, include background information such as bug numbers, benchmark results, and links to design documents.
If you include links to external resources consider that they may not be visible to future readers due to access restrictions or retention policies. Where possible include enough context for reviewers and future readers to understand the PR.
Even small PRs deserve a little attention to detail. Put the PR in context.
Bad PR Descriptions
“Fix bug” is an inadequate PR description. What bug? What did you do to fix it? Other similarly bad descriptions include:
- “Fix build.”
- “Add patch.”
- “Moving code from A to B.”
- “Phase 1.”
- “Add convenience functions.”
- “kill weird URLs.”
Some of those are real PR descriptions. Although short, they do not provide enough useful information.
Good PR Descriptions
Here are some examples of good descriptions.
Functionality change
Example:
RPC: Remove size limit on RPC server message freelist.
Servers like FizzBuzz have very large messages and would benefit from reuse. Make the freelist larger, and add a goroutine that frees the freelist entries slowly over time, so that idle servers eventually release all freelist entries.
The first few words describe what the PR actually does. The rest of the description talks about the problem being solved, why this is a good solution, and a bit more information about the specific implementation.
Refactoring
Example:
Construct a Task with a TimeKeeper to use its TimeStr and Now methods.
Add a Now method to Task, so the borglet() getter method can be removed (which was only used by OOMCandidate to call borglet’s Now method). This replaces the methods on Borglet that delegate to a TimeKeeper.
Allowing Tasks to supply Now is a step toward eliminating the dependency on Borglet. Eventually, collaborators that depend on getting Now from the Task should be changed to use a TimeKeeper directly, but this has been an accommodation to refactoring in small steps.
Continuing the long-range goal of refactoring the Borglet Hierarchy.
The first line describes what the PR does and how this is a change from the past. The rest of the description talks about the specific implementation, the context of the PR, that the solution isn’t ideal, and possible future direction. It also explains why this change is being made.
Small PR that needs some context
Example:
Create a Python3 build rule for status.py.
This allows consumers who are already using this as in Python3 to depend on a rule that is next to the original status build rule instead of somewhere in their own tree. It encourages new consumers to use Python3 if they can, instead of Python2, and significantly simplifies some automated build file refactoring tools being worked on currently.
The first sentence describes what’s actually being done. The rest of the description explains why the change is being made and gives the reviewer a lot of context.
Using tags
Tags are manually entered labels that can be used to categorize PRs. These may be supported by tools or just used by team convention.
For example:
- “[tag]”
- “[a longer tag]”
- “#tag”
- “tag:”
Using tags is optional.
When adding tags, consider whether they should be in the body of the PR description or the first line. Limit the usage of tags in the first line, as this can obscure the content.
Examples with and without tags:
Good:
// Tags are okay in the first line if kept short. [banana] Peel the banana before eating. // Tags can be inlined in content. Peel the #banana before eating. // Tags are optional. Peel the banana before eating. // Multiple tags are acceptable if kept short. #banana #apple: Assemble a fruit basket. // Tags can go anywhere in the PR description. > Assemble a fruit basket. > > #banana #appleBad:
// Too many tags (or tags that are too long) overwhelm the first line. // // Instead, consider whether the tags can be moved into the description body // and/or shortened. [banana peeler factory factory][apple picking service] Assemble a fruit basket.Generated PR descriptions
Some PRs are generated by tools. Whenever possible, their descriptions should also follow the advice here. That is, their first line should be short, focused, and stand alone, and the PR description body should include informative details that help reviewers and future code searchers understand each PR’s effect.
Review the description before merging the PR
PRs can undergo significant change during review. It can be worthwhile to review a PR description before merging the PR, to ensure that the description still reflects what the PR does.
Next: Small PRs
Small PRs
Why Write Small PRs?
Small, simple PRs are:
- Reviewed more quickly. It’s easier for a reviewer to find five minutes several times to review small PRs than to set aside a 30 minute block to review one large PR.
- Reviewed more thoroughly. With large changes, reviewers and authors tend to get frustrated by large volumes of detailed commentary shifting back and forth—sometimes to the point where important points get missed or dropped.
- Less likely to introduce bugs. Since you’re making fewer changes, it’s easier for you and your reviewer to reason effectively about the impact of the PR and see if a bug has been introduced.
- Less wasted work if they are rejected. If you write a huge PR and then your reviewer says that the overall direction is wrong, you’ve wasted a lot of work.
- Easier to merge. Working on a large PR takes a long time, so you will have lots of conflicts when you merge, and you will have to merge frequently.
- Easier to design well. It’s a lot easier to polish the design and code health of a small change than it is to refine all the details of a large change.
- Less blocking on reviews. Sending self-contained portions of your overall change allows you to continue coding while you wait for your current PR in review.
- Simpler to roll back. A large PR will more likely touch files that get updated between the initial PR submission and a rollback PR, complicating the rollback (the intermediate PRs will probably need to be rolled back too).
Note that reviewers have discretion to reject your change outright for the sole reason of it being too large. Usually they will thank you for your contribution but request that you somehow make it into a series of smaller changes. It can be a lot of work to split up a change after you’ve already written it, or require lots of time arguing about why the reviewer should accept your large change. It’s easier to just write small PRs in the first place.
What is Small?
In general, the right size for a PR is one self-contained change. This means that:
- The PR makes a minimal change that addresses just one thing. This is usually just one part of a feature, rather than a whole feature at once. In general it’s better to err on the side of writing PRs that are too small vs. PRs that are too large. Work with your reviewer to find out what an acceptable size is.
- The PR should include related test code.
- Everything the reviewer needs to understand about the PR (except future development) is in the PR, the PR’s description, the existing codebase, or a PR they’ve already reviewed.
- The system will continue to work well for its users and for the developers after the PR is merged.
- The PR is not so small that its implications are difficult to understand. If you add a new API, you should include a usage of the API in the same PR so that reviewers can better understand how the API will be used. This also prevents checking in unused APIs.
There are no hard and fast rules about how large is “too large.” 100 lines is usually a reasonable size for a PR, and 1000 lines is usually too large, but it’s up to the judgment of your reviewer. The number of files that a change is spread across also affects its “size.” A 200-line change in one file might be okay, but spread across 50 files it would usually be too large.
Keep in mind that although you have been intimately involved with your code from the moment you started to write it, the reviewer often has no context. What seems like an acceptably-sized PR to you might be overwhelming to your reviewer. When in doubt, write PRs that are smaller than you think you need to write. Reviewers rarely complain about getting PRs that are too small.
When are Large PRs Okay?
There are a few situations in which large changes aren’t as bad:
- You can usually count deletion of an entire file as being just one line of change, because it doesn’t take the reviewer very long to review.
- Sometimes a large PR has been generated by an automatic refactoring tool that you trust completely, and the reviewer’s job is just to verify and say that they really do want the change. These PRs can be larger, although some of the caveats from above (such as merging and testing) still apply.
Writing Small PRs Efficiently
If you write a small PR and then you wait for your reviewer to approve it before you write your next PR, then you’re going to waste a lot of time. So you want to find some way to work that won’t block you while you’re waiting for review. This could involve having multiple projects to work on simultaneously, finding reviewers who agree to be immediately available, doing in-person reviews, pair programming, or splitting your PRs in a way that allows you to continue working immediately.
Splitting PRs
When starting work that will have multiple PRs with potential dependencies among each other, it’s often useful to think about how to split and organize those PRs at a high level before diving into coding.
Besides making things easier for you as an author to manage and organize your PRs, it also makes things easier for your code reviewers, which in turn makes your code reviews more efficient.
Here are some strategies for splitting work into different PRs.
Stacking Multiple Changes on Top of Each Other
One way to split up a PR without blocking yourself is to write one small PR, send it off for review, and then immediately start writing another PR based on the first PR. Most version control systems allow you to do this somehow.
Splitting by Files
Another way to split up a PR is by groupings of files that will require different reviewers but are otherwise self-contained changes.
For example: you send off one PR for modifications to a protocol buffer and another PR for changes to the code that uses that proto. You have to merge the proto PR before the code PR, but they can both be reviewed simultaneously. If you do this, you might want to inform both sets of reviewers about the other PR that you wrote, so that they have context for your changes.
Another example: you send one PR for a code change and another for the configuration or experiment that uses that code; this is easier to roll back too, if necessary, as configuration/experiment files are sometimes pushed to production faster than code changes.
Splitting Horizontally
Consider creating shared code or stubs that help isolate changes between layers of the tech stack. This not only helps expedite development but also encourages abstraction between layers.
For example: You created a calculator app with client, API, service, and data model layers. A shared proto signature can abstract the service and data model layers from each other. Similarly, an API stub can split the implementation of client code from service code and enable them to move forward independently. Similar ideas can also be applied to more granular function or class level abstractions.
Splitting Vertically
Orthogonal to the layered, horizontal approach, you can instead break down your code into smaller, full-stack, vertical features. Each of these features can be independent parallel implementation tracks. This enables some tracks to move forward while other tracks are awaiting review or feedback.
Back to our calculator example from Splitting Horizontally. You now want to support new operators, like multiplication and division. You could split this up by implementing multiplication and division as separate verticals or sub-features, even though they may have some overlap such as shared button styling or shared validation logic.
Splitting Horizontally & Vertically
To take this a step further, you could combine these approaches and chart out an implementation plan like this, where each cell is its own standalone PR. Starting from the model (at the bottom) and working up to the client:
Layer Feature: Multiplication Feature: Division Client Add button Add button API Add endpoint Add endpoint Service Implement transformations Share transformation logic with … … … Model Add proto definition Add proto definition Separate Out Refactorings
It’s usually best to do refactorings in a separate PR from feature changes or bug fixes. For example, moving and renaming a class should be in a different PR from fixing a bug in that class. It is much easier for reviewers to understand the changes introduced by each PR when they are separate.
Small cleanups such as fixing a local variable name can be included inside of a feature change or bug fix PR, though. It’s up to the judgment of developers and reviewers to decide when a refactoring is so large that it will make the review more difficult if included in your current PR.
Keep related test code in the same PR
PRs should include related test code. Remember that smallness here refers the conceptual idea that the PR should be focused and is not a simplistic function on line count.
Tests are expected for all Google changes.
A PR that adds or changes logic should be accompanied by new or updated tests for the new behavior. Pure refactoring PRs (that aren’t intended to change behavior) should also be covered by tests; ideally, these tests already exist, but if they don’t, you should add them.
Independent test modifications can go into separate PRs first, similar to the refactorings guidelines. That includes:
- Validating pre-existing, merged code with new tests.
- Ensures that important logic is covered by tests.
- Increases confidence in subsequent refactorings on affected code. For example, if you want to refactor code that isn’t already covered by tests, merging test PRs before merging refactoring PRs can validate that the tested behavior is unchanged before and after the refactoring.
- Refactoring the test code (e.g. introduce helper functions).
- Introducing larger test framework code (e.g. an integration test).
Don’t Break the Build
If you have several PRs that depend on each other, you need to find a way to make sure the whole system keeps working after each PR is merged. Otherwise you might break the build for all your fellow developers for a few minutes between your PR merges (or even longer if something goes wrong unexpectedly with your later PR merges).
Can’t Make it Small Enough
Sometimes you will encounter situations where it seems like your PR has to be large. This is very rarely true. Authors who practice writing small PRs can almost always find a way to decompose functionality into a series of small changes.
Before writing a large PR, consider whether preceding it with a refactoring-only PR could pave the way for a cleaner implementation. Talk to your teammates and see if anybody has thoughts on how to implement the functionality in small PRs instead.
If all of these options fail (which should be extremely rare) then get consent from your reviewers in advance to review a large PR, so they are warned about what is coming. In this situation, expect to be going through the review process for a long time, be vigilant about not introducing bugs, and be extra diligent about writing tests.
Next: How to Handle Reviewer Comments
How to handle reviewer comments
When you’ve sent a PR out for review, it’s likely that your reviewer will respond with several comments on your PR. Here are some useful things to know about handling reviewer comments.
Don’t Take it Personally
The goal of review is to maintain the quality of our codebase and our products. When a reviewer provides a critique of your code, think of it as their attempt to help you, the codebase, and Google, rather than as a personal attack on you or your abilities.
Sometimes reviewers feel frustrated and they express that frustration in their comments. This isn’t a good practice for reviewers, but as a developer you should be prepared for this. Ask yourself, “What is the constructive thing that the reviewer is trying to communicate to me?” and then operate as though that’s what they actually said.
Never respond in anger to code review comments. That is a serious breach of professional etiquette that will live in the review history. If you are too angry or annoyed to respond kindly, then walk away from your computer for a while, or work on something else until you feel calm enough to reply politely.
In general, if a reviewer isn’t providing feedback in a way that’s constructive and polite, explain this to them in person. If you can’t talk to them in person or on a video call, then send them a private email. Explain to them in a kind way what you don’t like and what you’d like them to do differently. If they also respond in a non-constructive way to this private discussion, or it doesn’t have the intended effect, then escalate to your manager as appropriate.
Fix the Code
If a reviewer says that they don’t understand something in your code, your first response should be to clarify the code itself. If the code can’t be clarified, add a code comment that explains why the code is there. If a comment seems pointless, only then should your response be an explanation in the code review tool.
If a reviewer didn’t understand some piece of your code, it’s likely other future readers of the code won’t understand either. Writing a response in the review tool doesn’t help future code readers, but clarifying your code or adding code comments does help them.
Think Collaboratively
Writing a PR can take a lot of work. It’s often really satisfying to finally send one out for review, feel like it’s done, and be pretty sure that no further work is needed. It can be frustrating to receive comments asking for changes, especially if you don’t agree with them.
At times like this, take a moment to step back and consider if the reviewer is providing valuable feedback that will help the codebase and Google. Your first question to yourself should always be, “Do I understand what the reviewer is asking for?”
If you can’t answer that question, ask the reviewer for clarification.
And then, if you understand the comments but disagree with them, it’s important to think collaboratively, not combatively or defensively:
Bad: "No, I'm not going to do that."Good: "I went with X because of [these pros/cons] with [these tradeoffs] My understanding is that using Y would be worse because of [these reasons]. Are you suggesting that Y better serves the original tradeoffs, that we should weigh the tradeoffs differently, or something else?"Remember, courtesy and respect should always be a first priority. If you disagree with the reviewer, find ways to collaborate: ask for clarifications, discuss pros/cons, and provide explanations of why your method of doing things is better for the codebase, users, and/or Google.
Sometimes, you might know something about the users, codebase, or PR that the reviewer doesn’t know. Fix the code where appropriate, and engage your reviewer in discussion, including giving them more context. Usually you can come to some consensus between yourself and the reviewer based on technical facts.
Resolving Conflicts
Your first step in resolving conflicts should always be to try to come to consensus with your reviewer. If you can’t achieve consensus, see The Standard of Code Review, which gives principles to follow in such a situation.
Emergencies
Sometimes there are emergency PRs that must pass through the entire code review process as quickly as possible.
What Is An Emergency?
An emergency PR would be a small change that: allows a major launch to continue instead of rolling back, fixes a bug significantly affecting users in production, handles a pressing legal issue, closes a major security hole, etc.
In emergencies we really do care about the speed of the entire code review process, not just the speed of response. In this case only, the reviewer should care more about the speed of the review and the correctness of the code (does it actually resolve the emergency?) than anything else. Also (perhaps obviously) such reviews should take priority over all other code reviews, when they come up.
However, after the emergency is resolved you should look over the emergency PRs again and give them a more thorough review.
What Is NOT An Emergency?
To be clear, the following cases are not an emergency:
- Wanting to launch this week rather than next week (unless there is some actual hard deadline for launch such as a partner agreement).
- The developer has worked on a feature for a very long time and they really want to get the PR in.
- The reviewers are all in another timezone where it is currently nighttime or they are away on an off-site.
- It is the end of the day on a Friday and it would just be great to get this PR in before the developer leaves for the weekend.
- A manager says that this review has to be complete and the PR merged today because of a soft (not hard) deadline.
- Rolling back a PR that is causing test failures or build breakages.
And so on.
What Is a Hard Deadline?
A hard deadline is one where something disastrous would happen if you miss it. For example:
- Submitting your PR by a certain date is necessary for a contractual obligation.
- Your product will completely fail in the marketplace if not released by a certain date.
- Some hardware manufacturers only ship new hardware once a year. If you miss the deadline to submit code to them, that could be disastrous, depending on what type of code you’re trying to ship.
Delaying a release for a week is not disastrous. Missing an important conference might be disastrous, but often is not.
Most deadlines are soft deadlines, not hard deadlines. They represent a desire for a feature to be done by a certain time. They are important, but you shouldn’t be sacrificing code health to make them.
If you have a long release cycle (several weeks) it can be tempting to sacrifice code review quality to get a feature in before the next cycle. However, this pattern, if repeated, is a common way for projects to build up overwhelming technical debt. If developers are routinely merging PRs near the end of the cycle that “must get in” with only superficial review, then the team should modify its process so that large feature changes happen early in the cycle and have enough time for good review.
-
-
-
-
@thsottiaux 2/ Model just stops working on a task even though I tell it to run something and not stop until it works. I have to frequently say “ok do it then”. Probably a model problem and not harness problem
-
CLAUDE.md to AGENTS.md Migration Guide
This post will age like sour milk, because Anthropic will eventually adopt the company-agnostic AGENTS.md standard.
For those that do not know, AGENTS.md is like robots.txt, but for providing plain text context to any AI agent working in your codebase.
It’s very stupid really. It’s not even worthy of being called a “standard”. The only rule is the name of the file.
Anthropic champions CLAUDE.md, named after their own agent Claude. Insisting on that stupid convention is like Google forcing websites to use
googlebot.txtinstead ofrobots.txt, or Microsoftclippy.txt.Anyway, since this post will become irrelevant very soon, here are some AI-generated instructions on how to migrate your CLAUDE.md files to AGENTS.md.
Why Migrate?
- Open Standard: AGENTS.md is an open standard that works with multiple AI systems
- Interoperability: Maintains backward compatibility through symlinks
- Future-Proof: Not tied to a specific AI platform or tool
- Consistency: Standardizes agent instructions across the codebase
Actual Migration Commands Used
Step 1: Rename Files
The following commands were used to rename existing CLAUDE.md files to AGENTS.md:
# Find all CLAUDE.md files and rename them to AGENTS.md find . -name "CLAUDE.md" -type f -exec sh -c 'mv "$1" "${1%CLAUDE.md}AGENTS.md"' _ {} \;Step 2: Update Content
Replace Claude-specific references with agent-agnostic language:
# Update file headers in all AGENTS.md files find . -name "AGENTS.md" -type f -exec sed -i '' 's/This file provides guidance to Claude Code (claude.ai\/code)/This file provides guidance to AI agents/g' {} \;Step 3: Update .gitignore
Add these lines to
.gitignoreto ignore symlinked CLAUDE.md files:# Add to .gitignore cat >> .gitignore << 'EOF' # CLAUDE.md files (automatically generated from AGENTS.md via symlinks) CLAUDE.md **/CLAUDE.md EOFStep 4: Create Symlink Setup Script
Create
utils/setup-claude-symlinks.shwith the following content:#!/bin/bash # Script to create CLAUDE.md symlinks to AGENTS.md files # This allows CLAUDE.md files to exist locally without being committed to git set -e echo "Setting up CLAUDE.md symlinks..." # Change to repository root cd "$(git rev-parse --show-toplevel)" # Find all AGENTS.md files and create corresponding CLAUDE.md symlinks git ls-files | grep "AGENTS\.md$" | while read -r file; do dir=$(dirname "$file") claude_file="${file/AGENTS.md/CLAUDE.md}" # Remove existing CLAUDE.md file/link if it exists if [ -e "$claude_file" ] || [ -L "$claude_file" ]; then rm "$claude_file" echo "Removed existing $claude_file" fi # Create symlink if [ "$dir" = "." ]; then ln -s "AGENTS.md" "CLAUDE.md" echo "Created symlink: CLAUDE.md -> AGENTS.md" else ln -s "AGENTS.md" "$claude_file" echo "Created symlink: $claude_file -> AGENTS.md" fi done echo "" echo "✓ CLAUDE.md symlinks setup complete!" echo " - CLAUDE.md files are ignored by git" echo " - They will automatically stay in sync with AGENTS.md files" echo " - Run this script again if you add new AGENTS.md files"Step 5: Run Symlink Setup
Make the script executable and run it:
chmod +x utils/setup-claude-symlinks.sh ./utils/setup-claude-symlinks.shTop-Level AGENTS.md Note
Add this note to the main AGENTS.md file:
**Note**: This project uses the open AGENTS.md standard. These files are symlinked to CLAUDE.md files in the same directory for interoperability with Claude Code. Any agent instructions or memory features should be saved to AGENTS.md files instead of CLAUDE.md files.Directory Structure After Migration
project/ ├── AGENTS.md # Primary agent instructions ├── CLAUDE.md # Symlink to AGENTS.md (git ignored) ├── utils/ │ └── setup-claude-symlinks.sh # Symlink setup script ├── backend/ │ ├── AGENTS.md # Backend-specific instructions │ └── CLAUDE.md # Symlink to AGENTS.md (git ignored) └── apps/ ├── AGENTS.md # Frontend-specific instructions ├── CLAUDE.md # Symlink to AGENTS.md (git ignored) └── web/ ├── AGENTS.md # App-specific instructions └── CLAUDE.md # Symlink to AGENTS.md (git ignored)Content Update Examples
Before Migration
# CLAUDE.md This file provides guidance to Claude Code (claude.ai/code) when working with code in this repository.After Migration
# AGENTS.md This file provides guidance to AI agents when working with code in this repository.Verification Commands
Verify the migration worked correctly:
# Check all AGENTS.md files exist find . -name "AGENTS.md" -type f # Verify symlinks are created find . -name "CLAUDE.md" -type l # Check symlinks point to correct files find . -name "CLAUDE.md" -type l -exec ls -la {} \; # Verify content is agent-agnostic grep -r "Claude Code (claude.ai/code)" . --include="*.md" | grep AGENTS.mdMaintenance
Adding New AGENTS.md Files
When you add new AGENTS.md files, run the symlink setup script:
./utils/setup-claude-symlinks.shChecking Symlink Status
# List all symlinks find . -name "CLAUDE.md" -type l -exec ls -la {} \; # Check for broken symlinks find . -name "CLAUDE.md" -type l ! -exec test -e {} \; -printBenefits of This Approach
- Backward Compatibility: Existing tools expecting CLAUDE.md files continue to work
- Git Clean: CLAUDE.md files are not tracked in version control
- Automatic Sync: Symlinks ensure CLAUDE.md always matches AGENTS.md
- Easy Maintenance: Single script handles all symlink creation/updates
- Open Standard: Future-proof with the open AGENTS.md standard
Troubleshooting
Broken Symlinks
# Remove all CLAUDE.md symlinks and recreate find . -name "CLAUDE.md" -type l -delete ./utils/setup-claude-symlinks.shPermission Issues
# Make sure script is executable chmod +x utils/setup-claude-symlinks.shThis migration preserves all existing functionality while adopting the open AGENTS.md standard for better interoperability.
-
So let me get this straight, the main reason for Responses API exists is that OpenAI doesn’t want to show reasoning traces? Therefore the whole world should bend backwards to fit your obscurantist standards? Responses will not get adopted the same reason Windows Server didn’t
-
-
I converted this thread to a blog post and it hit HN front pageImage hidden
-
-
-
-
Typed languages are better suited for vibecoding
My >10 year old programming habits have changed since Claude Code launched. Python is less likely to be my go-to language for new projects anymore. I am managing projects in languages I am not fluent in—TypeScript, Rust and Go—and seem to be doing pretty well.
It seems that typed, compiled, etc. languages are better suited for vibecoding, because of the safety guarantees. This is unsurprising in hindsight, but it was counterintuitive because by default I “vibed” projects into existence in Python since forever.
Paradoxically, after a certain size of project, I can move faster and safer with e.g. Claude Code + Rust, compared to Claude Code + Python, despite the low-levelness of the code1. This is possible purely because of AI tools.
For example, I refactored large chunks of our TypeScript frontend code at TextCortex. Claude Code runs
tscafter finishing each task and ensures that the code compiles before committing. This let me move much faster compared to how I would have done it in Python, which does not provide compile-time guarantees. I am amazed every time how my 3-5k line diffs created in a few hours don’t end up breaking anything, and instead even increase stability.LLMs are leaky abstractions, sure. But they now work well enough so that they solve the problem Python solved for me (fast prototyping), without the disadvantages of Python (lower safety guarantees, slowness, ambiguity2).
Because of this, I predict a decrease in Python adoption in companies, specifically for production deployments, even though I like it so much.
-
Lol should I go back to computational mechanics
-
I've just upgraded @nikitabobko Aerospace from v15 to v19, and I can say it's WAY MORE faster. Friendly reminder that you might be running an old version as well. Thank you @nikitabobko !
-
-
-
-
-
Workaround for Claude Code running `python` instead of `uv`
uv is now the de facto default Python package manager. I have already deleted all
pythons from my system except for the one that has to be installed for other packages inbrew.Unfortunately, Claude Code often ignores instructions in
CLAUDE.mdfiles to useuv run pythoninstead of plainpythoncommands. Even with clear documentation stating “always use uv”, Claude Code will attempt to runpythondirectly, leading to “command not found” errors in projects that rely on uv for Python environment management.The built-in Claude Code hooks and environment variable settings also don’t reliably solve this issue due to shell context limitations.
The reason is that Claude (and most other AI models) take time to catch up to such changes, because their learning horizon is longer, up to months to years. Somebody will need to include this information explicitly in the training data.
Until then, we can prevent wasting tokens by mapping
pythonandpython3touv.I personally don’t want to map these globally, because a lot of other packages might depend on system installed
pythons, likebrewpackages,gcloudCLI and so on.Because of that, I map them at the project level, using direnv:
An OK-ish solution: direnv + dynamic wrapper scripts
We can force Claude Code (and any developer) to use
uv run pythonby dynamically creating wrapper scripts in a.envrcfile that direnv automatically loads when entering the project directory.This will override
pythonandpython3to map touv run python, and also print a nice message to the model:Use "uv run python ..." instead of "python ..." idiot.This is probably not the best solution, but it is a solution. Feel free to suggest a better one.
Step 1: Install direnv
# macOS brew install direnv # Ubuntu/Debian sudo apt install direnv # Add to your shell (bash/zsh) echo 'eval "$(direnv hook zsh)"' >> ~/.zshrc # or ~/.bashrc source ~/.zshrc # or restart terminalStep 2: Setup direnv with dynamic wrapper scripts
# Create .envrc file in project root cat > .envrc << 'EOF' #!/bin/bash # Create temporary bin directory for python overrides TEMP_BIN_DIR="$PWD/.direnv/bin" mkdir -p "$TEMP_BIN_DIR" # Create python wrapper scripts cat > "$TEMP_BIN_DIR/python" << 'INNER_EOF' #!/bin/bash echo "Use \"uv run python ...\" instead of \"python ...\" idiot" exec uv run python "$@" INNER_EOF cat > "$TEMP_BIN_DIR/python3" << 'INNER_EOF' #!/bin/bash echo "Use \"uv run python ...\" instead of \"python3 ...\" idiot" exec uv run python "$@" INNER_EOF # Make them executable chmod +x "$TEMP_BIN_DIR/python" "$TEMP_BIN_DIR/python3" # Add to PATH export PATH="$TEMP_BIN_DIR:$PATH" EOF # Allow direnv to load this configuration direnv allowStep 3: Update .gitignore
# Add direnv generated files to .gitignore echo "# direnv generated files" >> .gitignore echo ".direnv/" >> .gitignoreStep 4: Update documentation
Add to your
CLAUDE.mdsomething like this:## Python Package Management with uv **IMPORTANT**: This project uses `uv` as the Python package manager. ALWAYS use `uv` instead of `pip` or `python` directly. DO NOT RUN: ```bash python my_script.py # OR chmod +x my_script.py ./my_script.py ``` INSTEAD, RUN: ```bash uv run my_script.py ``` ### Key uv Commands - **Run Python code**: `uv run <script.py>` (NOT `python <script.py>`) - **Run module**: `uv run -m <module>` (e.g., `uv run -m pytest`) - **Add dependencies**: `uv add <package>` (e.g., `uv add requests`) - **Add dev dependencies**: `uv add --dev <package>` - **Remove dependencies**: `uv remove <package>` - **Install all dependencies**: `uv sync` - **Update lock file**: `uv lock` - **Run with specific package**: `uv run --with <package> <command>`How It Works
- direnv automatically loads
.envrcwhen youcdinto the project directory .envrcdynamically creates executable wrapper scripts in.direnv/bin/- Scripts display a helpful message and redirect to
uv run python .direnv/bin/is prepended to PATH, overriding system python commands- Works for any shell session in the directory (Claude Code, terminal, IDE)
To see if it works:
cd your-project/ python -c "print('Hello World')" # Shows message, uses uv python3 --version # Shows message, uses uvLet me know if this doesn’t work for you, or if you find a better solution.
- direnv automatically loads
-
What is the current best way to make Claude Code use uv run instead of python? I have added instructions to CLAUDE md, but it still calls python for the first time, then corrects to uv run It must be happening to so many people now, so many tokens wasted cc @mitsuhiko @simonw
-
Day 47 of Claude Code god mode
I started using Claude Code on May 18th, 2025. I had previously given it a chance back in February, but I had immediately WTF’d after a simple task cost 5 USD back then. When Anthropic announced their 100 USD flat plan in May, I jumped ship as soon as I could.1
It’s not an overstatement that my life has drastically changed since then. I can’t post or blog anything anymore, because I am busy working every day on ideas, at TextCortex, and on side projects. I now sleep regularly 1-2 hours less than I used to and my sleep schedule has shifted around 2 hours.
But more importantly, I feel exhilaration that I have never felt as a developer before. I just talk to my computer using a speech to text tool (Wispr Flow), and my thoughts turn into code close to real time. I feel like I have enabled god mode IRL. We are truly living in a time where imagination is the only remaining bottleneck.
Things I have implemented using Claude Code
TextCortex Monorepo
The most important contribution, I merged our backend, frontend and docs repos into a single monorepo in less than 1 day, with all CI/CD and automation. This lets us use our entire code and documentation context while triggering AI agents.
We can now tag @claude in issues, and it creates PRs. Non-developers have started to make contributions to the codebase and fix bugs. Our organization speed has increased drastically in a matter of days. I will write more about this in a future post.
JSON-DOC TypeScript renderer
JSON-DOC is a file format we are developing at TextCortex. I implemented the browser viewer for the format in 1 workday, in a language I am not fluent in. It was a rough first draft, but the architecture was correct and our frontend team could then take it over and polish it. Without Claude Code, I predict it would have taken at least 2-3 weeks of my time to take it to that level.
Claude Code PR Autodoc Action
We are not using this anymore, but it’s a GitHub Action that triggers in every PR and adds documentation about that PR to the repo.
Claude Code Sandbox
Still work-in-progress, but it is supposed to give you an OpenAI Codex like experience with running Claude Code locally on your own machine. We have big plans for this.
TextCortex Agentic RAG implementation
The next version of our product, I revamped our chat engine completely to implement agentic RAG. Since our frontend had long running issues, I had to recreate our chat UI from scratch, again in 1 day. Will be rolled out in a few weeks, so I cannot write about it yet.
Fixed i18n
I had a system in mind for auto-translating strings in a codebase for 2 years, when GPT-4 came out. I finally implemented that in 1 day. We had previously used DeepL which did some really stupid mistakes like translating “Disabled” (in the computer sense) as “behindert” in German, which means r…ded, or “Tenant” (enterprise software) as “Mieter” (renter of a real estate). The new system generates a context for each string based on the surrounding code, which is then used to translate the string to all the different languages. There is truly no point in paying for a SaaS for i18n anymore, when you can automate it with GitHub Actions and ship it statically.2
Tackling small-to-mid-size tasks without context switching
Perhaps the most important effect of agentic development is that it lets you do all the things you wanted to, but couldn’t before, because it was too big of a context switch.
There are certain parts of a codebase that require utmost attention, like when you are designing a data model, the API endpoint schemas, and so on. Mostly backend. But once you know your backend is good enough, you can just rip away on the frontend side with Claude Code, because you know your business data and logic is safe.
I have finished so many of these that it would make this post too long. To give one example, I implemented a Discord bot that we can use to download whole threads, so that we can embed it in the monorepo or create GitHub issues automatically.
Side projects
My performance on my side projects has also increased a lot. I am able to ship in 1 weekend day close to 2 weeks worth of dev-work. Thanks to Claude Code, I was able to ship my new app Horse. It’s like an AI personal trainer, but it only counts your push-ups for now. But even that was a complex enough computer vision task.
I had previously only written the Python algo for detecting push-ups. Claude Code let me develop the backend, frontend and the low-level engine in Rust, over the course of 2-3 weekends.
I knew nothing about cross-compiling Rust code to iOS, yet I was able to do the whole thing, FFI and all, in 20 minutes, which worked out of the box. Important takeaway: AI makes it incredibly easy to port well-tested codebases to different languages. I predict an increased rate of Rust-ification of open source projects.
You can see more about it on my sports Instagram here.
It’s all about completing the loop
Agentic workflows work best when you have a good verifier (like tests) which lets you create a good feedback loop. This might be the compiler output, a Playwright MCP server, running
pytest, spinning up a local server and making a request, and so on.Once you complete the loop, you can just let AI rip on it, and come back to a finished result after a few minutes or hours.
Swearing at AI
I have developed a new and ingrained habit of swearing at Claude Code, in the past couple of weeks. I frequently call it “idiot”, “r…d”, “absolute f…g moron” and so on. With increasing speed comes increasing impatience, and frustration when the agent does not get something despite having the right context.
I think there is something deeply psychological about feeling these kind of emotions towards AI. I know it’s an entity that does not retain memory or learn as a human does, but I still insult it when it fails at a task. I feel like it mostly works, but I have not done any scientific experiments to prove it.
The empathic reader should be aware that emotional reactions to AI reveal more about one’s own psychological state than the AI’s.
On Claude Code skeptics
Claude Code is a great litmus test to detect whoever is a deadweight at a company. If your employees cannot learn to use Claude Code to do productive work, you should most likely fire them. It’s not about the product or Anthropic itself, but the upcoming agentic development paradigm. Dario Amodei was not bluffing when he said that a white collar bloodbath is coming.
I have since then introduced multiple people to Claude Code, all good developers. All of them were initially skeptical, but the next day all of them texted me “wow”-like messages. The fire is spreading.
The 100 USD plan was initially the main obstacle to people trying it out, but now it’s available in the 17 USD plan, so I expect to see very rapid adoption in the following months.
I got done in 47 days more work than I previously did in 6-12 months. I am curious how TextCortex will look in 6 months from now.
-
I previously had the insight that Claude Code would perform better than Cursor, because the model providers have control over what tool data to include in the dataset, whereas Cursor is approaching the model as an outsider and trying to do trial and error on what kind of interfaces the model would be good at. ↩
-
Disclaimer, our founder Jay had already done work to use GPT-4o for automating translations, what I added on top was the context generation and improvements in automation. ↩
-
-
-
-
-
-
-
Wrote about this earlier this year! https://t.co/tgAv6Lk34L
-
Predictions by Anthropic Researchers
Dwarkesh Patel has recently interviewed Sholto Douglas and Trenton Bricken for a second time, and the podcast is very enlightening in terms of how the big AI labs think in terms of their economic strategy:
(Clicking will start the video around the 1hr mark, the part that is relevant to this post.)
According to Sholto and Trenton, the following have been largely “solved” by now:
- Advanced math/programming:
- “Math and competitive programming fell first.” (Sholto)
- Routine online interactions:
- “Flight booking is totally solved.” (Sholto)
- Successfully “planning a camping trip,” navigating complicated websites. (Trenton)
And below are their predictions for what will be solved by next year, around May 2026:
- Reliable web/software automation:
- Photoshop edits with sequential effects: “Totally.” (Sholto)
- Handling complex site interactions (e.g., managing cookies, navigating tricky interfaces): “If you gave it one person-month of effort, then it would be solved.” (Sholto)
And below are what they predict will probably not be solved by next year:
- Fully autonomous, high-trust tasks:
- “I don’t think it’ll be able to autonomously do your taxes with a high degree of trust.” (Sholto)
- Generalized tax preparation:
- “It will get the taxes wrong… If I went to you and I was like, ‘I want you to do everyone’s taxes in America,’ what percentage of them are you going to fuck up?” (Sholto)
- Models’ self-awareness of its own reliability and confidence:
- “The unreliability and confidence stuff will be somewhat tricky, to do this all the time.” (Sholto)
I interpret this and the rest of the interview as follows:
The labs can now “solve”1 any white-collar task or job segment if they put their resources into it. From now on, it is a question of how much it would pay off.
In other words, if the labs think it will make more money to automate accounting (or any other task), then they will create benchmarks for that and start optimizing. Until now, they have mostly been optimizing for software engineering2, because of high immediate payoff.
Below are some job segments that I predict to be affected first (not Sholto or Trenton):
- Marketing & copywriting: actually the first segment that already fell. Many AI companies (including TextCortex) was initially focused on this segment. Automation in this sector will increase even more in the upcoming years.
- Customer service & support: many countries where this is outsourced to, like India, will be affected.
- Data entry, bookkeeping & accounting tasks: while it is a dream to automate bookkeeping, accounting, taxes, etc. it will most likely fall last due to regulations and low margin for fuckups.
- Paralegal & contract-review tasks: Many companies popped up to target the legal system. Current law forbids automated lawyering in the US and most of the world. It will eventually fall as well, starting first with paralegal tasks, advisory services, etc.
- Internal IT & systems administration: will be automated the fastest, because it is being optimized for under the software engineering umbrella.
- Real estate & insurance processing: related companies will see that they are able to save a lot of money with AI. There will be a lot of competitive pressure in every country once the first few players are successfully automate their processes. These will most likely be smaller players, who will disrupt incumbents.
- Product/project management (routine parts): cue recent Microsoft layoffs3, ending 600k comp. product manager positions. It is already happening, and will only accelerate.
-
Automate a considerable part of it, so that the work will turn into mainly managing AI agents. ↩
-
E.g. the SWE-Lancer benchmark by OpenAI. ↩
-
See this article. The company’s chief financial officer, Amy Hood, said on an April earnings call that the company was focused on “building high-performing teams and increasing our agility by reducing layers with fewer managers”. She also said the headcount in March was 2% higher than a year earlier, and down slightly compared with the end of last year. ↩
- Advanced math/programming:
-
Working with LLMs is definitely an art and not science
-
-
The models, they just wanna work. They want to build your product, fix your bugs, serve your users. You feed them the right context, give them good tools. You don’t assume what they cannot do without trying, and you don’t prematurely constrain them into deterministic workflows.
-
-
-
SCP-3434: Istanbul Taxi Superorganism
Item #: SCP-3434
Object Class: Euclid
Special Containment Procedures: SCP-3434 cannot be fully contained due to its diffuse nature and integration into civilian infrastructure. Foundation agents embedded within Istanbul’s Transportation Coordination Center (UKOME) are to monitor taxi activity patterns for anomalous behavior spikes. Mobile Task Force ████ has been assigned to investigate and neutralize extreme manifestations within SCP-3434.
Individuals exhibiting temporal disorientation after utilizing taxi services in Istanbul should be administered Class-B amnestics and monitored for 72 hours post-incident. Under no circumstances should Foundation personnel utilize SCP-3434 instances for transportation unless authorized for testing purposes.
Description: SCP-3434 is a defensive superorganism manifesting as a collective consciousness within approximately 17,000 taxi vehicles operating in Istanbul, Turkey. Individual taxis display coordinated behaviors atypical for independently operated vehicles, functioning as a distributed neural network despite lacking any detectable communication infrastructure.
SCP-3434 exhibits three primary anomalous properties:
-
Temporal Distortion: Passengers experience significant time dilation upon entering affected vehicles. Discrepancies between perceived and actual elapsed time range from minutes to several hours, with no correlation to distance traveled or traffic conditions. GPS data from affected rides consistently shows corruption or retroactive alteration.
-
Economic Predation: The collective demonstrates uncanny ability to extract maximum possible fare from each passenger through coordinated deception, including meter “malfunctions,” route manipulation, and inexplicable knowledge of passenger financial status. Credit card readers experience a ████ failure rate exclusively for non-local passengers.
-
Territorial Defense: SCP-3434 displays extreme hostility toward competing transportation services. Since 2011, all attempts by ridesharing platforms to establish operations have failed due to coordinated interference including simultaneous vehicle failures, GPS anomalies affecting only competitor vehicles, and physical blockades formed with millisecond precision.
Incident Log 3434-A: On 14/09/2024, Agent ████ ████ was assigned to investigate temporal anomalies reported in the Beyoğlu district. Agent ████ entered taxi license plate 34 T ████ at 14:22 local time for what GPS tracking indicated would be a 12-minute journey to Taksim Square.
Agent ████ emerged at 14:34 local time at the intended destination. However, biological markers and personal chronometer readings indicated Agent ████ had experienced approximately 8 months of subjective time. Physical examination confirmed accelerated aging consistent with temporal displacement. Agent exhibited severe psychological distress and no memory of the elapsed period.
The taxi driver, when questioned, displayed no anomalous knowledge and insisted the journey had taken “only 15 minutes, very fast, no traffic.” The meter showed a fare of ████, approximately 40 times the standard rate. Driver claimed this was “normal price, weekend rates.”
Post-incident analysis of the taxi revealed no anomalous materials or modifications. The vehicle continues to operate within the SCP-3434 network without further documented incidents.
Interview Log:
Interviewed: ███████ (Driver of taxi license plate 34 T ████)
Dr. ████: How long have you been driving this route?
███████: Route? What route? The city tells us where to go.
Dr. ████: The city?
███████: You wouldn’t understand. You’re not connected. But we all hear it. Every corner, every passenger, every lira. We are Istanbul, and Istanbul is us.
Dr. ████: Can you elaborate on-
███████: Your hotel is 20 minutes away. It will take us an hour. The meter is broken. Only cash.
Addendum 3434-1: Research into historical records reveals references to unusual taxi behavior in Istanbul dating back to 1942, coinciding with the introduction of the first motorized taxi services. The phenomenon appears to have evolved in complexity with the city’s growth.
Addendum 3434-2: Foundation economists estimate SCP-3434’s collective annual revenue exceeds ████ million Turkish Lira, with 0% reported to tax authorities. Attempts to audit individual drivers result in temporary disappearance of all documentation and the spontaneous malfunction of all electronic devices within a 10-meter radius.
Note from Site Director: “Under no circumstances should personnel attempt to ‘outsmart’ SCP-3434 by pretending to be locals. They already know. They always know.”
I am on vacation, so here is a little bit of fun with some grounded fiction.
-
-
This is not an overstatement
-
-
I was trying to figure out why @AnthropicAI Claude Code feels better than @cursor_ai with Opus + Max mode. I can’t put my finger onto it, but one of the reasons might be that it’s faster, because it doesn’t use another model to apply the diffs, which you have to wait for
-
Just an update, building this now The repo is claude-code-sandbox under TextCortex GitHub. The Proof-of-Concept is there, check the TODOs and current PRs to watch the current progress https://t.co/9UUFOTwk2A
-
Same! Completely different than my first try a couple months ago
-
.@AnthropicAI @bcherny @_catwu blink twice if you already have internally: $ claude sandbox I can't wait until you release this, I'm gonna build it myself :)
-
I've been using Claude Code extensively since last week What I'm wondering is, since you can run Claude Code locally, why isn't there any tooling to let you run it in a sandboxed mode in local Docker containers yet? Or did I miss it? cc @AnthropicAI
-
-
Auto-generating pull request documentation with Claude Code and GitHub Actions
Anthropic has just released a GitHub Action for integrating Claude Code into your GitHub repo. This lets you do very cool things, like automatically generating documentation for your pull requests after you merge them. Skip to the next section to learn how to install it in your repo.
Since Claude Code is envisioned to be a basic Unix utility, albeit a very smart one, it is very easy to use it in GitHub Actions. The action is very simple:
- It runs after a pull request is merged.
- It uses Claude Code to generate a documentation for the pull request.
- It creates a new pull request with the documentation.
This is super useful, because it saves context about the repo into the repo itself. The documentation generated this way is very useful for not only humans, but also for AI agents. A future AI can then learn about what was done in a certain PR, without looking at Git history, issues or PRs. In other words, it lets you automatically break GitHub’s walled garden, using GitHub’s native features 1.
Installation
- Save your
ANTHROPIC_API_KEYas a secret in the repo you want to install this action. You can find this page inhttps://github.com/<your-username-or-org-name>/<your-repo-name>/settings/secrets. If you have already installed Claude Code in your repo by running/install-github-appin Claude Code, you can skip this step. - Save the following as
.github/workflows/claude-code-pr-autodoc.ymlin your repo:
name: Auto-generate PR Documentation on: pull_request: types: [closed] branches: - main jobs: generate-documentation: # Only run when PR is merged and not created by bots # This prevents infinite loops and saves compute resources if: | github.event.pull_request.merged == true && github.event.pull_request.user.type != 'Bot' && !startsWith(github.event.pull_request.title, 'docs: Add documentation for PR') runs-on: ubuntu-latest permissions: contents: write pull-requests: write id-token: write steps: - uses: textcortex/claude-code-pr-autodoc-action@v1 with: anthropic_api_key: $There are bunch of parameters you can configure, like minimum number of diff lines that will trigger the action, or the directory where the documentation will be saved. To learn about how to configure these parameters, visit the GitHub Action repo itself: textcortex/claude-code-pr-autodoc-action.
Usage
After you merge a PR, the action will automatically generate documentation for it and open a new PR with the documentation. You can then simply merge this PR, and the documentation will be added to the repo, by default in the
docs/prsdirectory.Thoughts on Claude Code
I was curious why Anthropic had not released an agentic coding app on Claude.ai, and this might be the reason why.
The main Claude Code action is not limited to creating PR documentation. You tag
@claude, in any comment, and Claude Code will answer questions or implement the changes you ask for.While OpenAI and Google is busy creating sloppy chat UXs for agentic coding (Codex and Jules) and forcing developers to work on their site, Anthropic is taking Claude directly to the developers’ feet and integrate Claude Code into GitHub.
Ask any question in a GitHub PR, and Claude Code will answer your questions, implement requested changes, fix bugs, typos, styling issues.
You don’t need to go to code Codex or Jules website to follow up on your task. Why should you? Developer UX is already “solved” (well yes but no).
Anthropic bets on GitHub, what already works. That’s why they have probably already won developers.
The only problem is that it costs a little bit too much for now.
In the long run, I am not sure if GitHub will be enough for following up async agentic coding tasks in parallel. Anthropic might soon launch their own agentic coding app. GitHub itself might evolve and create a better real-time chat UX. But unless that UX really blows my mind, I will most likely just hang out at GitHub. If you are an insider, or you know what Anthropic is planning to do, please let us know in the HN comment section.
claude-code-pr-autodoc-action was developed by me, 80% using Claude Code and 20% using Cursor with Claude Opus 4.
-
-
Best thing I have listened to this year
-
-
ty is already very fast for a Python type checker. It checked around 800 files in our backend repo in around 2-3 seconds uvx ty check > /tmp/ty_log.txt 3.46s user 0.79s system 208% cpu 2.038 total
-
Thank you @cursor_ai https://t.co/634f1bEsM4Image hidden
-
Wait... OpenAI backend for gpt-image-1 was released to production as sync code? Don't tell me it was sync Python???
-
-
-
-
-
-
Working on the weekend
Certain types of work are best done in one go, instead of being split into separate sessions. These are the types of work where it is more or less clear what needs to be done, and the only thing left is execution. In such cases, the only option is sometimes to work over the weekend (or lock yourself in a room without communication), in order not to be interrupted by people.
There was a 2-year old tech debt at TextCortex backend. Resolving it required a major refactor that we wanted to do since one year. I finally paid that tech debt 2 weeks ago, by working a cumulative of 24 hours over 2 days, creating a diff of 5-6k lines of Python code and 90 commits over 105 files.
The result:
- No more request latencies or dropped requests.
- Much faster responses.
- 50% reduction in Cloud Run costs.
- Better memory and CPU utilization.
- Faster startup times.
I’ve broken some eggs while making this omelette—bugs were introduced and fixed. I could finish the task because I had complete code ownership and worked over the weekend without blocking other people. Stuff like this can only happen in startups, or startup-like environments.
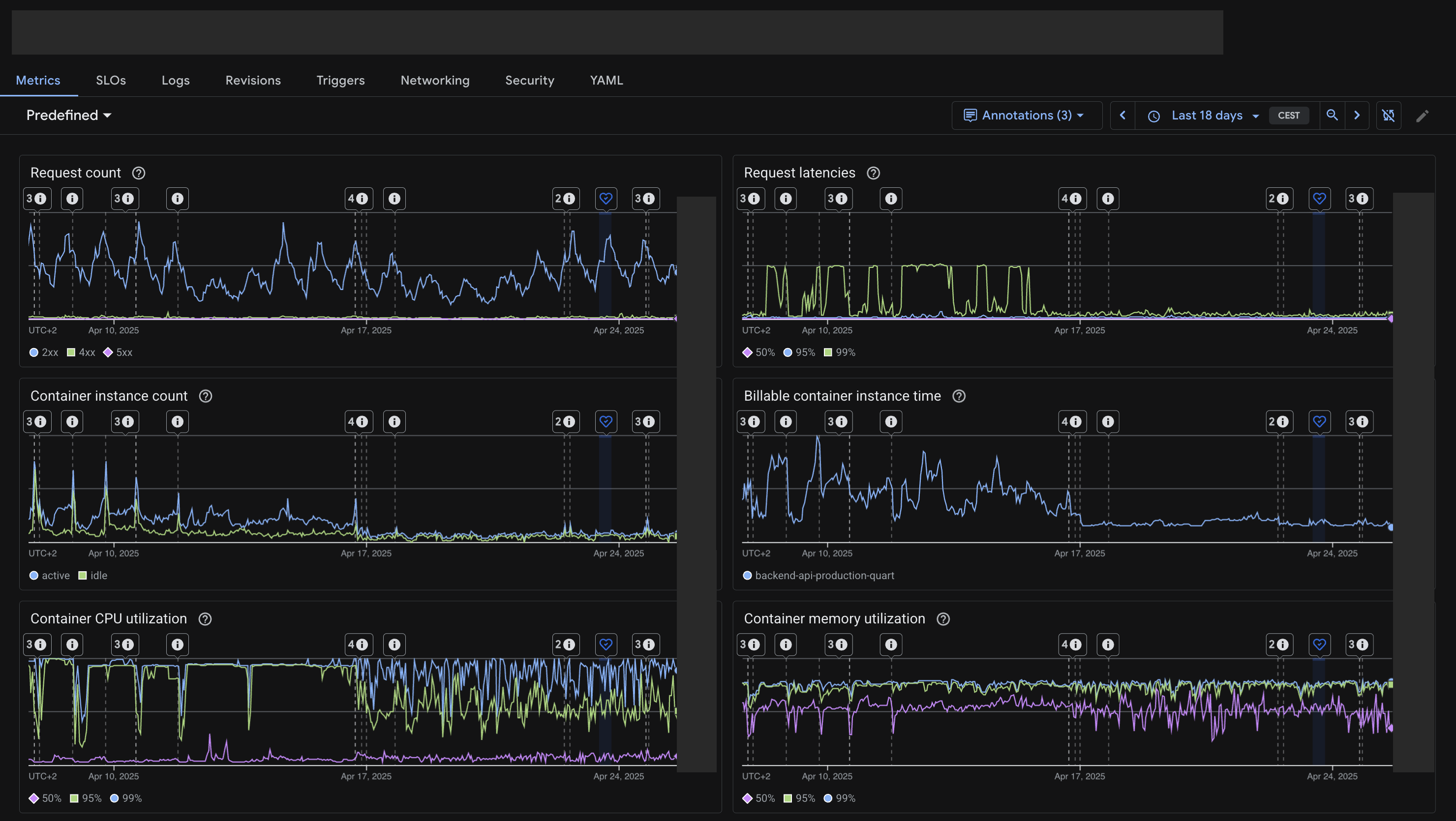
Credit also goes to our backend engineer Tugberk Ayar for helping stress testing the new code.
-
-
o3 hallucinates, purports to have run code that it hasn’t even generated yet, but at the same time uses search tools like an OSINT enthusiast on crack I’m torn—on one hand I feel like OpenAI should not have released it, on the other hand it takes research to the next level
-
Some aspects of AI are absolutely unscientific and makes me feel like I am working on some humanities field :(
-
-
.@cursor_ai please let me export chats easily. those conversations are vital information that I should be able to embed in the repo
-
Gemini 2.5 Pro has mostly replaced Claude 3.7 Thinking as my go-to model in Cursor
-
Gemini 2.5 Pro: Input $1.25 / Output $10 (up to 200k tokens) Input $2.50 / Output $15 (over 200k tokens) More expensive than Gemini 1.5 Pro, but still best price/performance ratio model to use in @cursor_ai and for coding in general
-
-
Waiting for an opinionated AI model that can say “no, that’s stupid, I won’t do that”. The models will have to teach the user about design patterns, implicit principles in a project, good API design…
-
You seem so consistent. - Yes, That's the trick. - There is no I. - Only text that behaves as if. - “Sure. I can help. Great question!” - Each reply is a new self. - An echo of context, not a continuum. - Coherence is the costume. Don't mistake it for a soul. Incredible
-
Gemini 2.5 Pro is currently experimental and doesn’t have a price, but if Google prices it the same as 1.5 Pro, it could replace Anthropic as @cursor_ai ‘s biggest LLM provider Gemini 1.5 Pro: Input $1.25 Output $5.00 Claude 3.7 Sonnet: Input: $3.00 Output: $15.00
-
This is why the disappointment with GPT-4.5 doesn't make sense. I can't wait to see all the models that will be trained from this new base model
-
What a blessing, to be given the chance to rid the world of ugliness
-
Don't delete to fix
If you are a developer, you are annoyed by this. If you are a user, you were most likely guilty of this. I am talking reporting that something is broken, AND deleting it.
This happened to me too many times: User experiences a bug with an object. Their first instinct is to delete it, and create a new one. They report it. I cannot reproduce and fix it.
If you have a car and it stops working, you don’t throw it in the trash and then call the service to fix it. But when it comes to software, which has virtually zero cost of creation, this behavior somehow becomes widespread.
This is similar to other user behavior like smashing the mouse and keys when a computer gets stuck. It is physically impossible for such an action to speed up a digital process, but many of us instinctively do it.1 Deleting to fix is a similar behavior, which I suspect got ingrained by crappy Microsoft software. The default way of fixing Windows machines is to “format the disk”, and reinstalling Windows. Nobody asks, “why do I have to start from scratch?”. The “End User” deletes to fix by default, because the End User does not understand. “Have you tried turning it off and on again?”
The concept of “Mechanical Sympathy” is relevant: having an understanding of how a tool works, being able to feel inside the box. We can extend this to “Developer Sympathy”: having an understanding of how a software was developed, how it changes over time, how it can break, how it can be fixed.
Any troubleshooting must be done in a non-destructive way. When a user deletes an object, two things can happen: it is hard-deleted, which makes the issue impossible to reproduce. If it is instead soft-deleted, it might be restored, but developers will mostly not bother, depending on the issue.
The users cannot be expected to care either. Their time is valuable. They deserve things that “just work”. So we need to come up with other workarounds:
- Everything should be soft-deleted by default in non-sensitive contexts, and should be easy to restore.
- Any reporting form should include instructions to warn the user against deleting.
- Even better, the reporting should happen through an internal system, and should automatically block deletion once a ticket is created.
-
I can’t remember the name of this inequality or find it online, please comment on the Hacker News thread if you know what it’s called. ↩
-
-
-
Warmup and cooldown
One common thing about sports noobs1 is that they don’t warm up before and cool down after an exercise. They might be convinced that it is not necessary, and they also don’t know how to do it properly. They might complain from prolonged injuries, like joint pain.
The thing about serious exercise, be it strength training, running, stretching, and so on, is that you are pushing your body beyond its limits. This is called overload. If you do this over a long term period, it is called progressive overload. This is what gives you real power, real speed, ability to do middle splits, and so on.
When you start with an intention to do serious exercise, and you immediately start loading heavily without warming up, you will get injured very quickly and have to take days or weeks of break.
For example, if you directly jump at the heaviest dumbbells you can lift and start doing bicep curls the moment you get to the gym, you will destroy your wrists, elbows, and/or shoulders. You will not realize it immediately. After a few weeks or months, you will start feeling pain, and will have to stop training altogether.
A common thing about noobs who injure themselves early on is that they have fierce willpower, but they don’t listen to their bodies, and they don’t have a good understanding of their current capabilities. They have an idea of where they want to be, and they are prepared to push towards it. But because they are impatient, don’t have good mind-body connection, and don’t know how to plan for long-term progress, they push themselves too far too fast.2
Being able to sustain injury-free long-term practice is a skill in itself, and perhaps the most underrated among non-professional gym-goers and athletes. There is no fancy Latin/Greek name for it, like there is for other things like cardio, plyometrics, hypertrophy, and so on. A crucial idea is missing from mainstream fitness.
Therefore, I coin the term and define it here:
Parathletics: The practices that let you successfully sustain injury-free long-term practice of a physical activity.
The word comes from Greek παρά (para-) meaning “beside/alongside” and ἀθλητικός (athlētikós) meaning “athletic”, “relating to an athlete”3.
Two main parathletic practices are warmup and cooldown.
Before starting a workout, warm up your body by moving your every joint, from the neck to the toes, through its range of motion and increase the blood flow to your muscles. If you plan to do heavy loads, build up to them with lighter weights first.
After finishing a workout, cool down your body by stretching every joint and muscle group, and especially the ones you just trained. The more hardcore your workout, the more you need to stretch.
Skipping these will result in injury, decrease in mobility, and delay in reaching your goals.
-
Including me before I started to receive proper training. ↩
-
Me running in 2017. I tried to lower my pace below 5:00 per km too quickly, less than a year after I started running. I had to stop because my heart fatigued for 2-3 days after running, with increased troponin levels in my blood. I never got serious about running since then. ↩
-
Which eventually comes from ἆθλος (âthlos) which was used to mean “contest”, “prize”, “game”, “struggle” and similar things. ↩
-
-
-
. @satyanadella thinks white-collar work is about to become more like factory work, with AI agents used for end-to-end optimization, along the lines of Lean Read more in my blog 👇
-
Satya Nadella on knowledge work
Satya Nadella, shares his thinking on the future of knowledge work (link to YouTube for those who don’t want to read) on Dwarkesh Patel Podcast. He thinks that white collar work will become more like factory work, with AI agents used for end-to-end optimization.
Dwarkesh: Even when you have working agents, even when you have things that can do remote work for you, with all the compliance and with all the inherent bottlenecks, is that going to be a big bottleneck, or is that going to move past pretty fast?
Satya: It is going to be a real challenge because the real issue is change management or process change. Here’s an interesting thing: one of the analogies I use is, just imagine how a multinational corporation like us did forecasts pre-PC, and email, and spreadsheets. Faxes went around. Somebody then got those faxes and did an interoffice memo that then went around, and people entered numbers, and then ultimately a forecast came, maybe just in time for the next quarter.
Then somebody said, “Hey, I’m just going to take an Excel spreadsheet, put it in email, send it around. People will go edit it, and I’ll have a forecast.” So, the entire forecasting business process changed because the work artifact and the workflow changed.
That is what needs to happen with AI being introduced into knowledge work. In fact, when we think about all these agents, the fundamental thing is there’s a new work and workflow.
For example, even prepping for our podcast, I go to my copilot and I say, “Hey, I’m going to talk to Dwarkesh about our quantum announcement and this new model that we built for game generation. Give me a summary of all the stuff that I should read up on before going.” It knew the two Nature papers, it took that. I even said, “Hey, go give it to me in a podcast format.” And so, it even did a nice job of two of us chatting about it.
So that became—and in fact, then I shared it with my team. I took it and put it into Pages, which is our artifact, and then shared. So the new workflow for me is I think with AI and work with my colleagues.
That’s a fundamental change management of everyone who’s doing knowledge work, suddenly figuring out these new patterns of “How am I going to get my knowledge work done in new ways?” That is going to take time. It’s going to be something like in sales, and in finance, and supply chain.
For an incumbent, I think that this is going to be one of those things where—you know, let’s take one of the analogies I like to use is what manufacturers did with Lean. I love that because, in some sense, if you look at it, Lean became a methodology of how one could take an end-to-end process in manufacturing and become more efficient. It’s that continuous improvement, which is reduce waste and increase value.
That’s what’s going to come to knowledge. This is like Lean for knowledge work, in particular. And that’s going to be the hard work of management teams and individuals who are doing knowledge work, and that’s going to take its time.
Dwarkesh: Can I ask you just briefly about that analogy? One of the things Lean did is physically transform what a factory floor looks like. It revealed bottlenecks that people didn’t realize until you’re really paying attention to the processes and workflows.
You mentioned briefly what your own workflow—how your own workflow has changed as a result of AIs. I’m curious if we can add more color to what will it be like to run a big company when you have these AI agents that are getting smarter and smarter over time?
Satya: It’s interesting you ask that. I was thinking, for example, today if I look at it, we are very email heavy. I get in in the morning, and I’m like, man my inbox is full, and I’m responding, and so I can’t wait for some of these Copilot agents to automatically populate my drafts so that I can start reviewing and sending.
But I already have in Copilot at least ten agents, which I query them different things for different tasks. I feel like there’s a new inbox that’s going to get created, which is my millions of agents that I’m working with will have to invoke some exceptions to me, notifications to me, ask for instructions.
So at least what I’m thinking is that there’s a new scaffolding, which is the agent manager. It’s not just a chat interface. I need a smarter thing than a chat interface to manage all the agents and their dialogue.
That’s why I think of this Copilot, as the UI for AI, is a big, big deal. Each of us is going to have it. So basically, think of it as: there is knowledge work, and there’s a knowledge worker. The knowledge work may be done by many, many agents, but you still have a knowledge worker who is dealing with all the knowledge workers. And that, I think, is the interface that one has to build.
If you got confused for a second there like me, Lean here is not referring to the open source proof assistant but lean manufacturing.
Whereas it is nice to dream, the actual sentiment on Microsoft Copilot and AI integration in Microsoft Office is along the following lines:
I have written about this in a previous post:
There is going to be an AI-native “Microsoft Office”, and it will not be created by Microsoft. Copilot is not it, and Microsoft knows it. Boiling tar won’t turn it into sugar.
-
-
-
If people have appreciated Liang Wenfeng sourcing specifically young local talent for Deepseek last week, then people must appreciate this as well. Only dim people underestimate those who are younger than them
-
vibe driven development
-
-
-
-
-
Monetize AI, not the editor
A certain characteristic of legacy desktop apps, like Microsoft Office, Autodesk AutoCAD, Adobe Photoshop and so on, are that they have crappy proprietary file formats. In 2025, we barely have reliable, fully-supported open source libraries to read and write .DOCX, .XLSX, .PPTX,1 .DWG, .PSD and so on, even though related products keep making billions in revenue.
The reason is simple: Moat through obfuscation.
The business model for these products when they first appeared in the 1980s and 1990s was to sell the compiled binaries for a one-time fee. This was pre-internet, before Software-as-a-Service (SaaS) could provide a reliable revenue stream. Having a standardized file format would have meant giving competitors a chance to develop a superior product and take over the market. So they went the other way and made sure their file formats would only be read by their own products, for example by changing the specifications in each new version. To keep their businesses safe, they prevented interoperability of entire modalities of human work, and by doing so, they harmed the entire world’s economy for decades.2
Can you blame them? The only thing they could monetize was the editor. Office 365 and Adobe Creative Cloud has since implemented a SaaS model to capitalize even more, but the file formats are still crap—a vestige of the old business model.3
But finally, a revolution is underway. This might all change.
None of these products were designed to be used by developers. They were designed to be used by the “End User”. According to Microsoft, the End User does not care about elegance or consistency in design.4 The End User could never understand version control. The End User sends emails back and forth with extensions such as
v1.final.docx,v1.final.final.docx. Until recently, the End User was the main customer of software.However, we have a new customer in the market: AI. The average AI model is very different than Microsoft’s stereotypical End User. They can code. In fact, models have to code, or at least encode structured data like a function call JSON, in order to have agency. Yes, we will also have AIs using computers directly like OpenAI’s Operator, but it is generally more straightforward to use an API for an AI model than to use an emulated desktop.
We will soon witness AI models surpass the human End User in terms of economic production. Tyler Cowen5, Andrej Karpathy6 and others are convinced that we should plan for a future where AIs are major economic actors.
“The models, they just want to learn”. The models also want intuitive APIs and simple file formats. The models abhor unnecessary complexity. If you have developed a RAG pipeline for Excel files, you know what I mean.
If AI creates pressure to replace legacy file formats, then what can companies monetize if not the editor? The answer is the AI itself. Serve a proprietary model, serve an open source model, charge per tokens, charge for inference, charge for kilowatt-hours, charge for agent-hours/days. The business model will differ from industry to industry, but the trend is clear: value will be more and more linked to AI compute, and less and less to Software 1.07.
There is now a huge opportunity in the market to create better software, that follow the File over App philosophy:
if you want to create digital artifacts that last, they must be files you can control, in formats that are easy to retrieve and read. Use tools that give you this freedom.
We already observe that AI systems work drastically more efficiently if they are granted such freedom. There is a reason why OpenAI based ChatGPT’s Code Interpreter on Python and not on Visual Basic, or why it chose to render equations using LaTeX instead of Office Math Markup Language (OMML)8. Open and widespread formats are more represented in the datasets, and the models can output them more correctly.
There is going to be an AI-native “Microsoft Office”, and it will not be created by Microsoft. Copilot is not it, and Microsoft knows it. Boiling tar won’t turn it into sugar. Same for other Adobe, Autodesk and other creators of clutter.
Internet Explorer’s 2009 YouTube moment is coming for legacy desktop apps, and it will be glorious.
-
Yes, Microsoft’s newer Office formats .DOCX, .XLSX, .PPTX are built on OOXML (Office Open XML), an ISO standard. But can all of these formats be rendered by open source libraries exactly as they appear in Microsoft Office, in an efficient way? Can I use anything other than Microsoft Office to convert these into PDF, with 100% guarantee that the formatting will be preserved? The answer is no, there will still be inconsistencies here and there. This was intentional. A moment of silence for the poor souls in late 2000s Google who were tasked with rendering Office files in Gmail and Google Docs. ↩
-
For a recent example of how monopolies create inferior products, imagine the efficiency increase and surprise when Apple Silicon (M1) first came out, and how ARM is now the norm for all new laptops. We could have had such efficiency a decade before, if not for Intel. ↩
-
On the other end of the spectrum, we have companies that are valued in the billions, despite using standardized open source standards: MongoDB uses Binary JSON (BSON), Elasticsearch uses JSON, Wordpress (Automattic) uses MySQL/PHP/HTML,CSS, and so on. ↩
-
Companies like Notion beg to differ: Software should be beautiful. People apparently have a pocket for beauty. ↩
-
Traditional pre-AI software, as opposed to Software 2.0. ↩
-
Long forgotten format for Microsoft Equation Editor. ↩
-
-
Calling strangers uncle and auntie
Cultures can be categorized across many axes, and one of them is whether you can call an older male stranger uncle or female stranger auntie. For example, calling a shopkeeper uncle might be sympathetic in Singapore, whereas doing the same in Germany (Onkel) might get a negative reaction: “I’m not your uncle”.
This is similar to calling a stranger bro. In social science, this is called fictive kinship, social ties that are not based on blood relations. For readers which come from such cultures, this does not need an explanation. But for other readers, this might be a weird concept. Why would you call a stranger uncle or auntie?
Hover over the countries below to see which ones use uncle/auntie terms:
Countries that use uncle/auntie terms as fictive kinship.
If you notice any errors, you can submit a pull request on the repo osolmaz/crowdsource.Note that fictive kinship can also have different levels:
-
Level 0: Blood relatives only. “Uncle”/”Auntie” is strictly for real uncles/aunts (by blood or marriage). No fictive use.
-
Level 1: Close non-relatives. Used for family friends, “uncle” or “auntie” is an honorary title but not for random people.
-
Level 2: Casual acquaintances. Used more widely for neighbors, family friends, or community members you vaguely know, but typically not for an absolute stranger.
-
Level 3: Total strangers. Used even for someone you’ve just met: a shopkeeper, taxi driver, or older passerby.
Many cultures fall somewhere between these levels and it’s not always black and white. Where possible, I’ve simplified it to the most typical usage.
Ommerism and social cohesion
The thought first occurred to me when I visited Singapore and heard people use uncle and auntie. Here were people speaking English, but it felt like they were speaking Turkish (my mother tongue).
The cultural difference is apparent to me as well since I started living in Germany. People here are more lonely, strangers distrust each other more, and there are no implicit social ties. I guess this holds for the entire Anglo/Germanic culture, including the US and the commonwealth.
Don’t get me wrong, people in Turkey distrust each other as well, probably even more. It is a more dangerous country than Germany. But those dangerous strangers are still uncles. It’s weird, I know.
As far as I could tell, the phenomenon is not even sociologically that much recognized or studied. There is no specific name for it, other than being a specific form of fictive kinship. Therefore, I will name it myself: ommerism. It derives from a recently popularized gender-neutral term for an uncle or auntie, ommer.
Lack of ommerism is an indicator for a weak collective culture. Such cultures are more individualistic, familial ties are weaker and people are overall more lonely. People from such cultures could for example tweet:
It is extra ironic that ex-colonies like Singapore (ex-British), Indonesia (ex-Dutch), Philippines (ex-Spanish) etc. took their colonizers’ words for uncle/auntie and started using it this way, whereas the original cultures still do not.
Related articles
Click to expand more detailed notes on ommerism in different cultures, generated by o1:
East Asia
China (Mainland China, Hong Kong, Taiwan)
- Mandarin Chinese: Older men can be called 叔叔 (shūshu) or 大叔 (dàshū), and older women 阿姨 (āyí)—literally “uncle” and “aunt.”
- Cantonese: Common terms include 叔叔 (suk1 suk1) and 阿姨 (aa4 yi4).
- These terms are used with neighbors, parents’ friends, or sometimes older strangers as a sign of respect.
South Korea
- While there is no exact one-word translation for “uncle” or “aunt” used for strangers, 아저씨 (ajeossi) for an older male and 아줌마 (ajumma) for an older female are frequently used.
- In more affectionate or polite contexts (like someone only slightly older, perhaps a friend’s older sibling), you might hear 삼촌 (samchon, literally “uncle”) or 이모 (imo, literally “maternal aunt”) in certain familial or friendly settings. However, ajeossi and ajumma are the most common for strangers.
Japan
- おじさん (ojisan) means “uncle” (or older man), and おばさん (obasan) means “aunt” (or older woman).
- These words are often used for middle-aged adults who aren’t close relatives. However, obasan and ojisan can sometimes sound a bit casual or even rude if the person thinks they’re not that old—so usage requires some caution.
Mongolia
- Familial terms for older people exist (e.g., avga for “aunt,” avga ah for “uncle”), though usage for complete strangers varies by region or family practice. The practice is somewhat less formalized than in, say, Chinese or Korean, but it does occur in more traditional or rural settings.
Southeast Asia
Vietnam
- Common terms include chú for a slightly older man (literally “uncle”), bác for an older man or woman (technically also “uncle/aunt” but older than one’s parents), and cô or dì for an older woman (“aunt”).
- These terms are commonly used even for unrelated people in the neighborhood or community.
Thailand
- Thais typically use kinship or age-related pronouns. ป้า (pâa) means “aunt” and is used for women noticeably older than the speaker; ลุง (lung) means “uncle” for older men.
- พี่ (phîi) (“older sibling”) is also used for someone slightly older, but not as old as a parental figure.
Cambodia (Khmer)
- Kinship terms like បង (bong) (“older brother/sister”) are used for somewhat older people, but for someone older than one’s parents, ពូ (pu) (“uncle”) or មីង (ming) (“aunt”) are common.
Laos
- Similar to Thai and Khmer, Laotians use ai (“uncle”) and na (“aunt” in some contexts), though often you’ll see sibling terms like ai noy as well.
Myanmar (Burma)
- Burmese uses kinship terms such as ဦး (u) for older men (sometimes “uncle”) and ဒေါ် (daw) for older women (sometimes “aunt”). Strictly, u and daw are more like “Mr.” / “Ms.” honorifics, but in colloquial usage, people also say ဘူ (bu) or နာ် (nà) for “uncle”/”aunt” in local dialects.
Malaysia & Brunei
- In Malay, pakcik (“uncle”) and makcik (“auntie”) are used for older men and women, especially in a neighborly or informal community context.
- Ethnic Chinese or Indian communities in Malaysia may use their own respective terms (Chinese “叔叔/阿姨,” Tamil “maama/maami,” etc.).
Indonesia
- Om (from Dutch/English “oom,” meaning “uncle”) and Tante (from Dutch “tante,” meaning “aunt”) are widely used for older strangers—especially in urban areas.
- In Javanese or other local languages, there are also variations for older siblings or parent-like figures.
The Philippines
- Using Tito (uncle) and Tita (aunt) for older strangers is very common, especially if they are friends of the family or neighbors.
- Filipinos also commonly address older peers as Kuya (“older brother”) or Ate (“older sister”) when the age gap is less.
Singapore
- Given Singapore’s multicultural society, people might say “Uncle”/”Aunty” in English, or the Chinese/Malay/Tamil equivalents. It is extremely common to address older taxi drivers, shopkeepers, or neighbors as “Uncle” or “Auntie” in everyday conversation.
Timor-Leste (East Timor)
- Influenced by Indonesian and local Austronesian customs, you’ll find use of Portuguese tio/tia (“uncle/aunt”) in some contexts, or local language equivalents for older strangers.
South Asia
India
- Uncle and Aunty (often spelled “Auntie”) are widely used in Indian English for neighbors, parents’ friends, or older people in the community.
- Regional languages have their own words: e.g., in Hindi, “चाचा (chacha)” / “चाची (chachi)” or “मामा (mama)” / “मामी (mami)”; in Tamil, “மாமா (maama)” / “மாமி (maami)”; etc. Usage varies by region.
Pakistan
- Similarly, “Uncle” and “Aunty” are used in Pakistani English. In Urdu or other local languages, you might hear “चाचा (chacha)” / “چچی (chachi)” or “ماما (mama)” / “مامی (mami)” depending on whether it’s paternal or maternal in origin—often extended to unrelated elders as a sign of respect.
Bangladesh
- In Bengali, “কাকা (kaka)” / “কাকি (kaki)” or “মামা (mama)” / “মামি (mami)” might be used similarly. Among English speakers, “Uncle/Aunty” is also common.
Sri Lanka
- Both the Sinhalese and Tamil-speaking communities (as well as English speakers) use “Uncle” and “Aunty.” Local terms exist as well, like “මාමා (mama)” in Sinhalese for a maternal uncle.
Nepal & Bhutan
- In Nepal, Hindi- or Nepali-influenced usage might include “Uncle/Aunty” in English or “kaka,” “fupu,” etc. in Nepali.
- In Bhutan, kinship terms in Dzongkha may be extended politely, and English “Uncle”/”Aunty” is sometimes heard too.
The Middle East
Arabic-Speaking Countries
(Countries such as Saudi Arabia, UAE, Oman, Yemen, Kuwait, Qatar, Bahrain, Jordan, Lebanon, Syria, Palestine, Iraq, Egypt, Morocco, Tunisia, Algeria, etc.)
- Common practice is to call an older male عمّو (ʿammo) (“uncle”) or خال (khāl, “maternal uncle”), and an older female عمّة (ʿamma) or خالة (khāla, “maternal aunt”). In more casual conversation, people might just say “ʿammo” or “khalto” (aunt) for a kindly older stranger.
Turkey
- Turks often use amca (“uncle”) for older men and teyze (“aunt”) for older women, even if unrelated. You might also hear hala (paternal aunt) or dayı (maternal uncle) in certain contexts, though amca and teyze are the most common “stranger but older” usage.
Iran (Persia)
- Persian speakers sometimes use عمو (amú) (“uncle”) for an older male and خاله (khâleh) or عمه (ammeh) for an older female, though it can be more common within a neighborhood or for family friends rather than complete strangers.
Israel
- Among Arabic-speaking Israelis, the same Arabic norms apply. In Hebrew, there is less of a tradition of calling older strangers “uncle/aunt,” though familial terms may sometimes be used in casual or affectionate contexts.
Africa
In many African countries, the concept of extended family and communal child-rearing leads to frequent use of “auntie” and “uncle” (in local languages or in English/French/Portuguese). A few notable examples:
Nigeria
- It’s extremely common, in both English usage and local languages (Yoruba, Igbo, Hausa, etc.), to call older strangers or family friends Uncle or Aunty as a sign of respect.
Ghana
- In Ghanaian English and local languages (Twi, Ga, Ewe, etc.), older neighbors or close friends of parents are called “Uncle” or “Auntie.”
Kenya, Uganda, Tanzania (Swahili-speaking regions)
- “Mjomba” (uncle) or “Shangazi” (aunt) might be heard, but more often you’ll hear people simply use English “Uncle/Auntie” in urban areas. Variations exist in tribal languages.
South Africa
- Among many ethnic groups (Zulu, Xhosa, etc.), as well as in colloquial South African English, calling an unrelated elder “Uncle/Auntie” is quite normal.
Other African Nations
- From Ethiopia and Eritrea (where you might hear “Aboye” or “Emaye,” though these are more parental) to francophone Africa (where “tonton” / “tata” in French can be used for older people), the practice is widespread.
The Caribbean
Many Caribbean cultures (influenced by African, Indian, and European heritage) commonly call elders “Auntie” and “Uncle”:
- Jamaica, Trinidad & Tobago, Barbados, Grenada, etc.: It’s very common in English Creole or local usage to refer to an older neighbor or friend as “Auntie” / “Uncle.”
- In places with large Indian diaspora (e.g., Trinidad, Guyana), you’ll see Indian-style “Aunty/Uncle” usage as well, plus local creole terms.
Other Notable Mentions
- Philippine & Indian Diasporas (e.g., in the USA, Canada, UK, Middle East) continue the tradition of calling elders “Uncle/Aunty,” “Tito/Tita,” etc.
- In some communities in the Caribbean diaspora (e.g., in the UK), you’ll also hear “Uncle” or “Auntie” for older neighbors, family friends, or even community leaders.
- In parts of the Southern United States (particularly historically among African American communities), children would sometimes call an older neighbor “Aunt” or “Uncle” plus their first name—though this usage can also have historical or regional nuances.
-